随着科技的飞速进步,我们正迈入一个由人工智能驱动的创意新时代。字节跳动的最新力作——OmniHuman技术,标志着这一进程的一个重要里程碑。这项革命性的技术彻底改变了内容创作的格局,它能够将单一的图像与音频相结合,通过其先进的算法,无缝编织成高质量的视频内容。这意味着,创作者们只需提供一张精心挑选的图片和对应的音频,OmniHuman即可魔术般地生成流畅、逼真的视频片段,极大地简化了视频制作流程,开启了个性化视频内容创作的新篇章。这一技术的问世,不仅提升了内容生产的效率,更为创意表达插上了翅膀,预示着一个更加丰富多元的数字媒体时代的到来。
字节跳动数字人团队最新发布的多模态数字人方案omnihuman,在肖像音频驱动技术领域取得突破性进展,其前身是曾在x平台引发热议的loopy技术。omnihuman能够基于单张图片和一段音频生成逼真生动的视频,显著提升了视频生成效果的自然度。

 OmniHuman生成的视频中人物动作自然流畅:
OmniHuman生成的视频中人物动作自然流畅:
该方案的核心优势在于其强大的单模型处理能力,能够兼容各种尺寸和人物占比的图片,并支持多种动作生成,包括演讲、唱歌、演奏乐器以及移动等,同时有效改善了现有技术中常见的手势变形问题。
更令人惊喜的是,OmniHuman还支持动漫和3D卡通等非真人图像的视频生成,并能很好地保留其原有风格。该技术已落地即梦AI平台,相关功能即将上线测试。
更多细节和演示效果,请访问:
项目主页: 技术报告:技术突破:
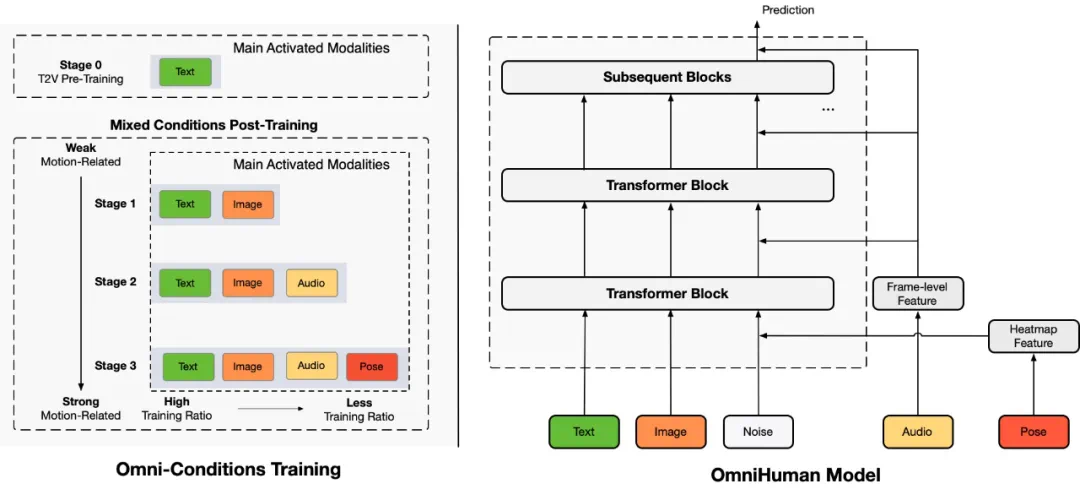
OmniHuman克服了现有技术对高度过滤训练数据和受限场景的依赖,通过创新的Omni-ConditionsTraining混合多模态训练策略,从大规模数据中学习,有效提升了模型的泛化能力和生成效果的自然度。该策略遵循两个核心原则:
利用较弱条件任务的数据来扩展较强条件任务的训练数据规模。 较强条件任务的训练比例应低于较弱条件任务。基于此,OmniHuman采用分阶段训练,逐步引入文本、图像、音频和姿态等多种模态数据,并调整其训练比例,最终实现单模型对多种模态的兼容和高效处理。

效果对比及结论:
OmniHuman在效果对比中展现出显著的优势,其单模型性能优于现有针对不同人物占比的专用模型。通过Omni-ConditionsTraining,模型在手势生成和多样化图像处理方面也取得了显著改进。
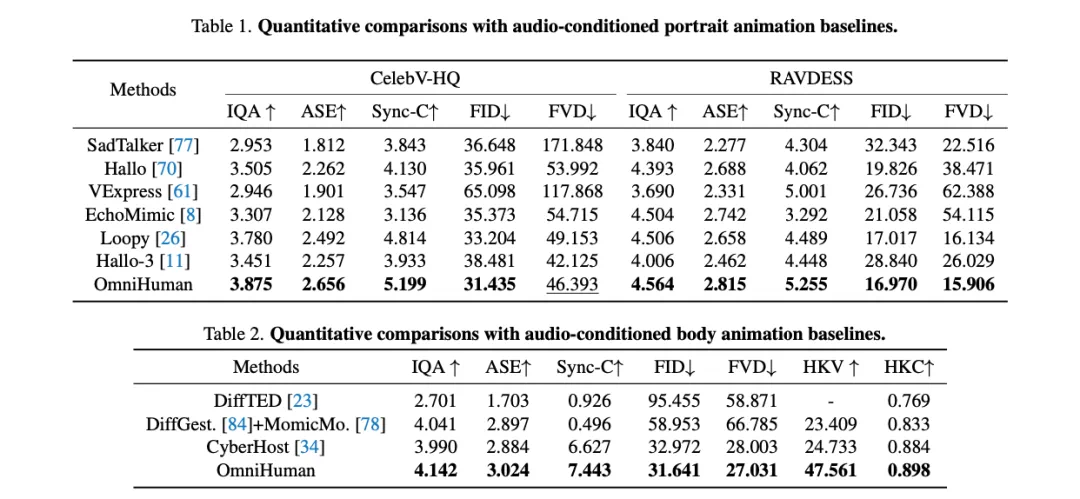
总而言之,OmniHuman是一个突破性的端到端多模态人像视频生成框架,它解决了高质量数据稀缺的问题,并能生成生动、高质量的人像动画视频,支持任意纵横比的图像输入。
团队介绍:
该技术由字节跳动智能创作数字人团队研发,该团队隶属于字节跳动AI&多媒体技术中台,致力于研发领先的智能创作技术,并为公司内部和外部合作伙伴提供相应的技术能力和解决方案。
以上就是AI「视觉图灵」时代来了!字节OmniHuman,一张图配上音频,就能直接生成视频的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 近期热点
近期热点 最新攻略
最新攻略













