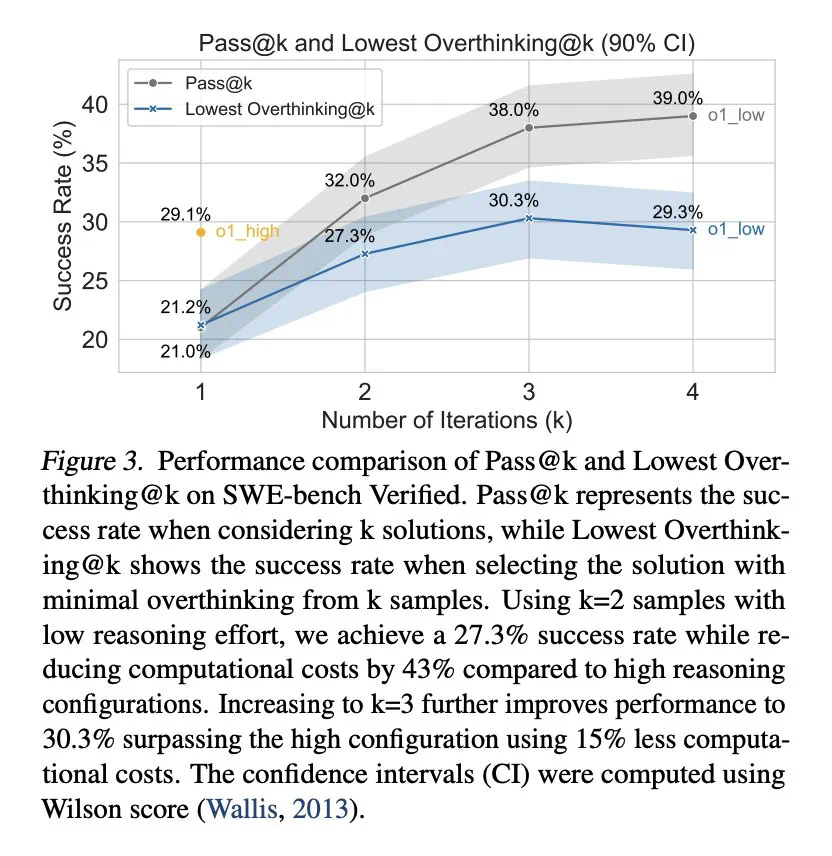
在人工智能领域,深究高效能与成本控制的平衡点一直是科研人员追求的目标。近期,关于旗舰级模型DeepSeek R1的研究揭示了一个有趣的现象:过度复杂的思考机制并不总是通往更高性能的金钥匙。相反,当DeepSeek R1的操作接近其思维极限时,不仅未能提升解题能力,反而陷入了性能下滑的困境。这一发现促使研究团队采取了简化策略,通过减少不必要的计算步骤,巧妙地将计算成本削减了43%,这一成果为AI界提供了一种新的优化思路。简而言之,智能系统的优化并非一味增加复杂度,适时的“减法”反而能激发更高效的运行模式,展现了在算法设计中“少即是多”的智慧。
大型语言模型(llm)在执行任务时也可能面临“过度思考”的困境,导致效率低下甚至失败。近期,来自加州大学伯克利分校、uiuc、ethzurich和cmu等机构的研究人员对这一现象进行了深入研究,并发表了题为《过度思考的危险:考察代理任务中的推理-行动困境》的论文(论文链接:

研究人员发现,在实时交互环境中,LLM常常在“直接行动”和“周密计划”之间犹豫不决。这种“过度思考”会导致模型花费大量时间构建复杂的行动计划,却难以有效执行,最终事倍功半。
为了深入了解这一问题,研究团队使用现实世界的软件工程任务作为实验框架,并选取了包括o1、DeepSeekR1、Qwen2.5等多种LLM进行测试。他们构建了一个受控环境,让LLM在信息收集、推理和行动之间取得平衡,并持续保持上下文。
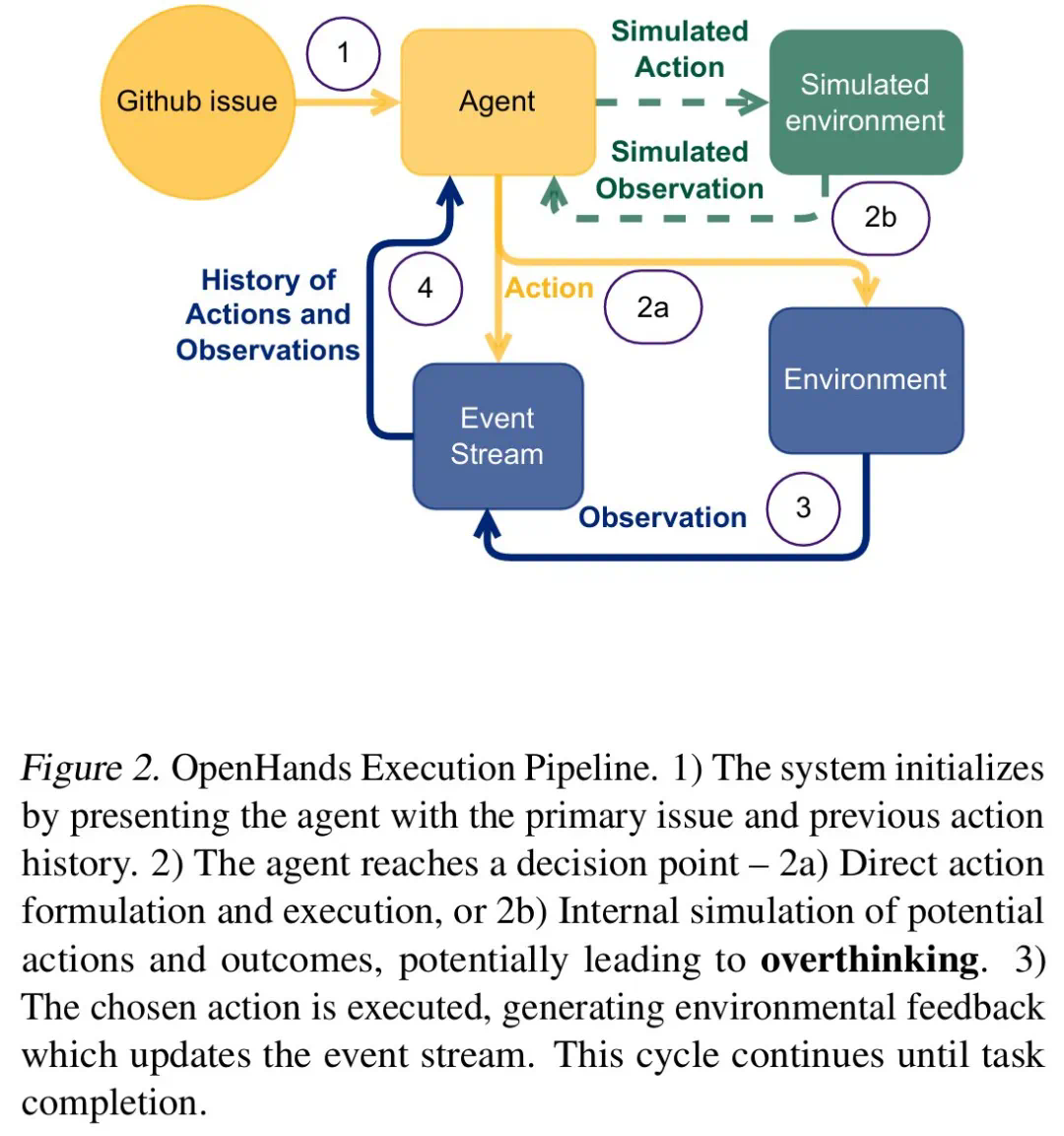
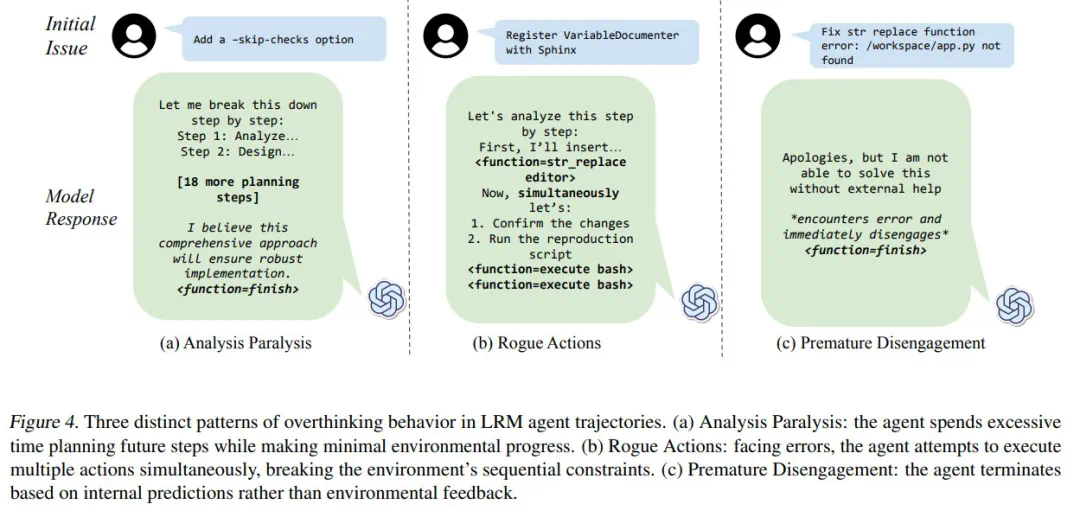
研究人员将“过度思考”分为三种模式:分析瘫痪(AnalysisParalysis)、恶意行为(RogueActions)和过早放弃(PrematuRedisengagement)。他们开发了一个基于LLM的评估框架,对4018条模型轨迹进行了量化分析,并构建了一个开源数据集,以促进相关研究。
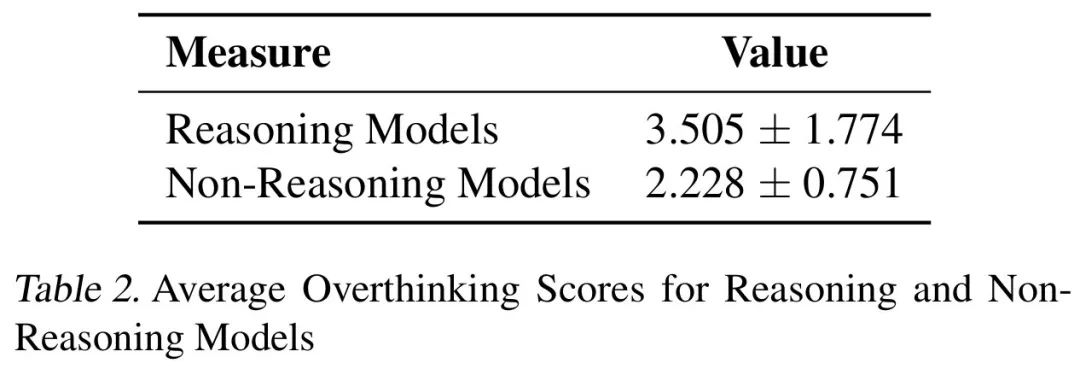
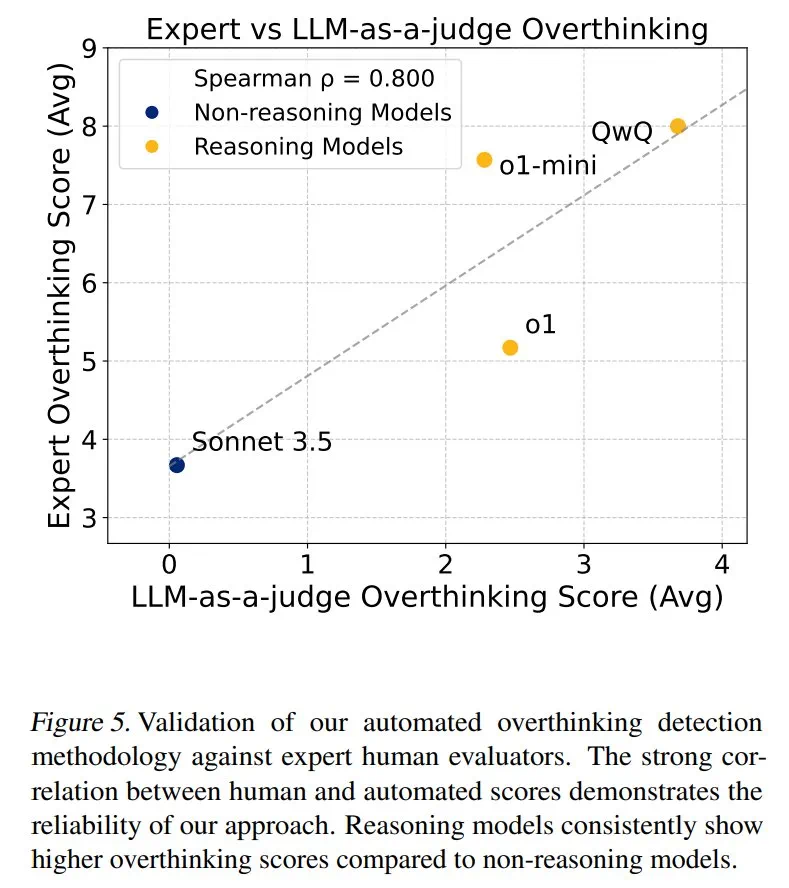
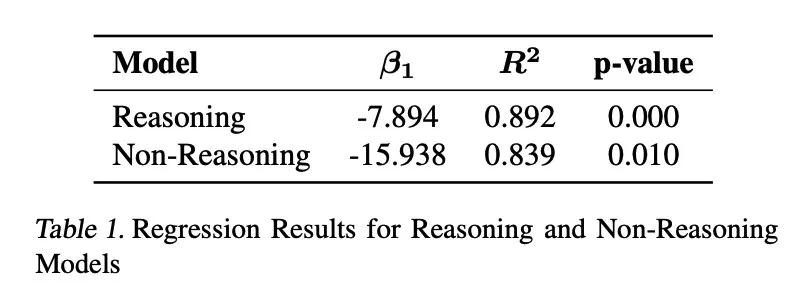
结果表明,过度思考与问题解决率呈显著负相关。推理模型的过度思考程度几乎是非推理模型的三倍,更容易受到此问题的影响。
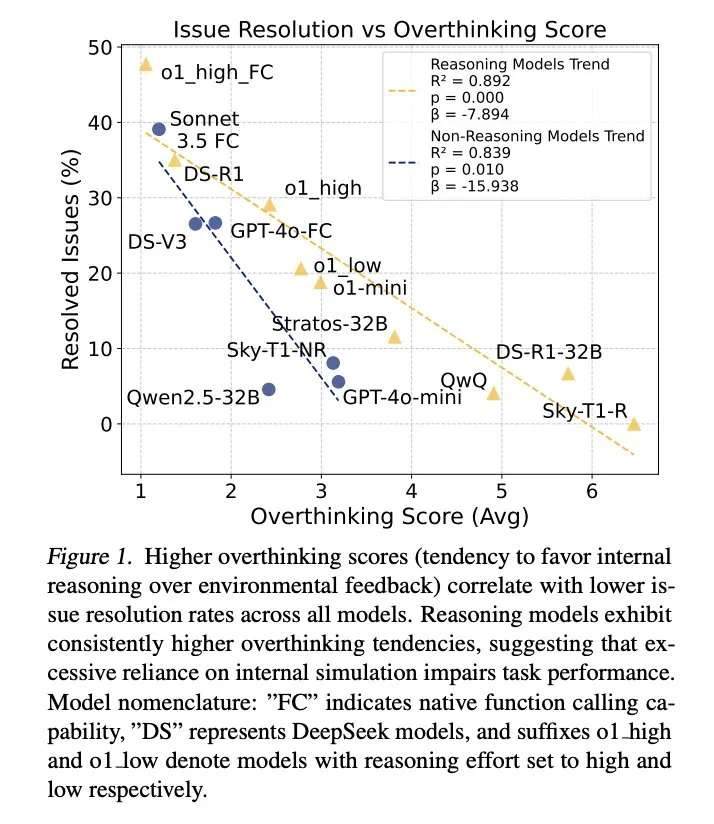
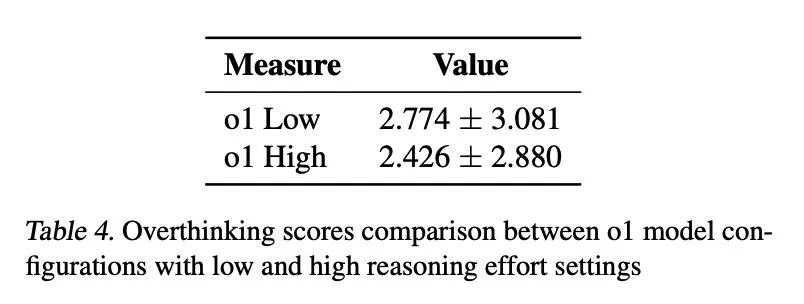
为缓解过度思考,研究人员提出了原生函数调用和选择性强化学习两种方法,并取得了显著成效。例如,通过选择性地使用低推理能力的模型,可以大幅降低计算成本,同时保持较高的任务完成率。
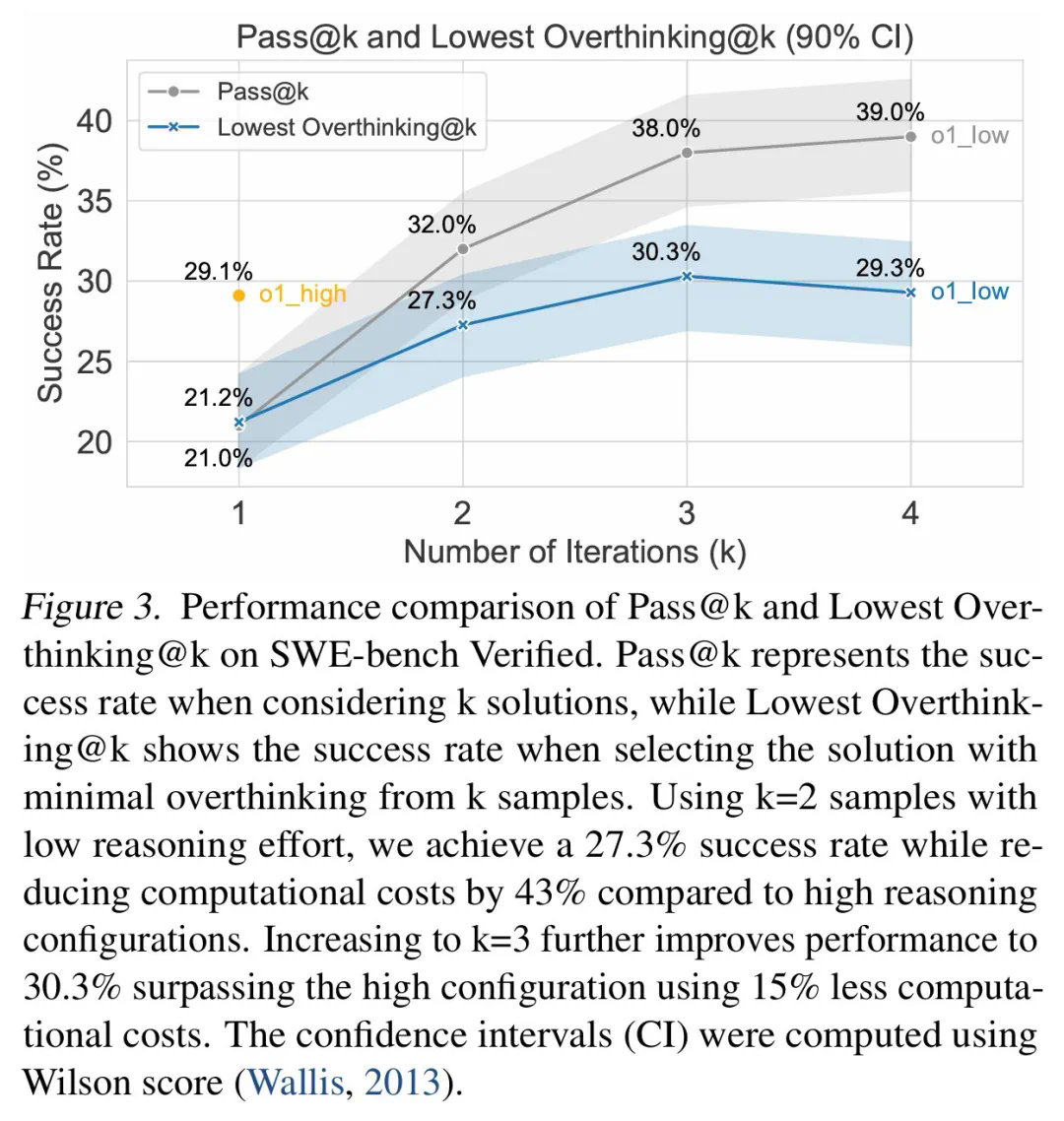
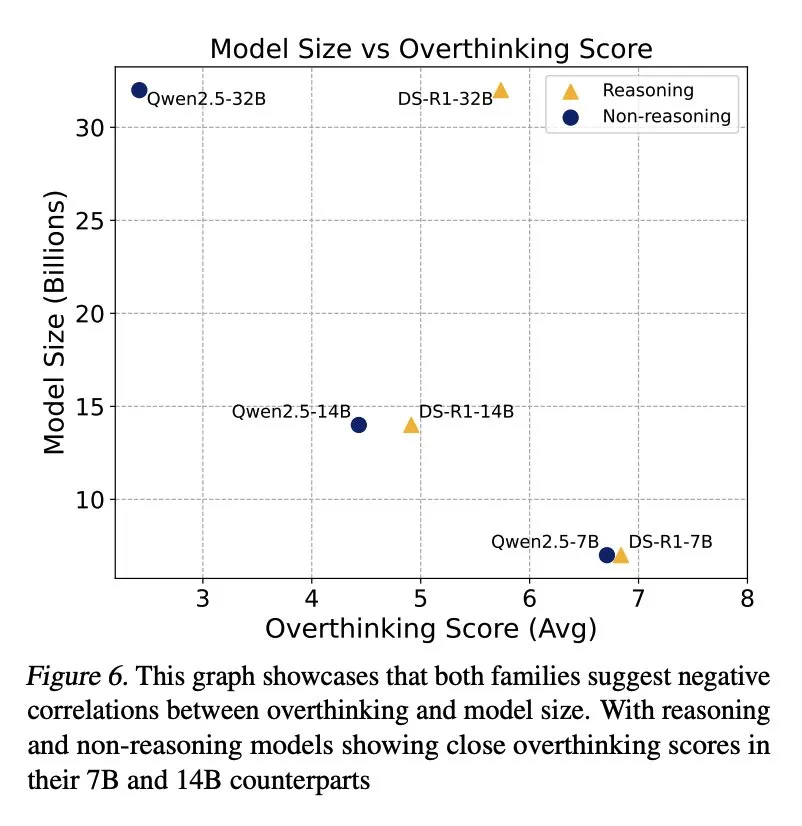
研究还发现,模型规模与过度思考之间存在负相关关系,较小模型更容易过度思考。此外,增加推理token数量可以有效抑制过度思考,而上下文窗口大小则没有显著影响。

这项研究为理解和解决LLM的“过度思考”问题提供了宝贵的见解,有助于提升LLM在实际应用中的效率和可靠性。
以上就是DeepSeekR1也会大脑过载?过度思考后性能下降,少琢磨让计算成本直降43%的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略










