在深度学习领域,DeepSeek作为一款强大的工具,因其在处理复杂数据集时展现出的卓越性能而备受推崇。然而,其核心组件之一——GRPO(Greedy Resource Allocation OpTIMization)算法,在执行过程中对内存资源的高需求,成为了众多研究者和实践者共同面临的挑战。这一问题不仅限制了DeepSeek在资源有限环境中的应用范围,也增加了训练与推理阶段的门槛。幸运的是,社区并未对此袖手旁观,不少技术爱好者和专家开始分享他们的破解之道,旨在减少GRPO的内存占用,从而提升DeepSeek的普及度和实用性。本文将简要介绍GRPO算法的内存优化策略,探讨这些创新方法如何通过智能内存管理、算法重构以及分布式计算策略,有效缓解DeepSeek在大规模应用中的内存瓶颈,为渴望深入探索深度学习领域的开发者们提供宝贵的思路和实践指导。
rtx3080移动版训练大型语言模型的实用指南
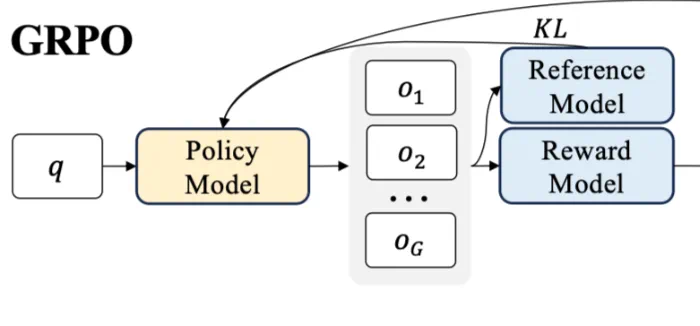
本文旨在指导GPU资源受限的开发者如何利用GRPO(GroupRelativePolicyOptimization)训练大型语言模型。DeepSeek-R1的发布使得GRPO成为强化学习训练大型语言模型的热门方法,因为它高效且易于训练。GRPO通过利用模型自身生成的训练数据进行迭代改进,目标是最大化生成文本的优势函数,同时保持模型与参考策略的接近性。
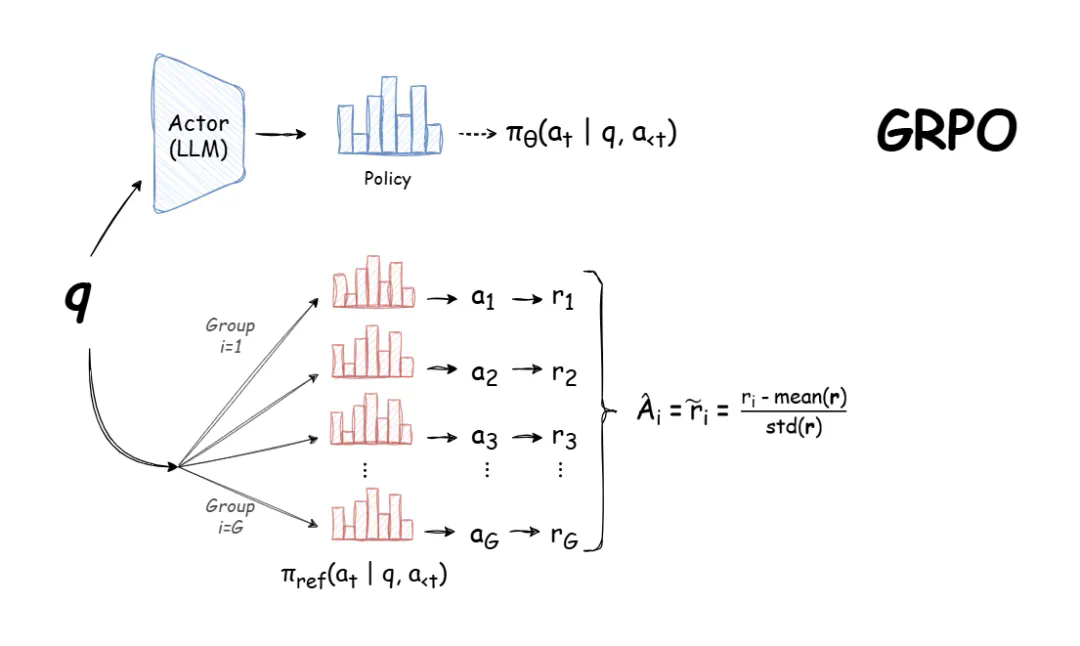
选择合适的模型大小和训练方法(全参数微调或参数高效微调-PEFT)是训练的关键。本文作者GregSchoeninger(Oxen.aiCEO)使用配备16GB显存的RTX3080笔记本电脑进行实验,并分享了其经验。
 原文链接:
原文链接:
作者在使用trl库的GRPO实现时,遇到了显存不足(OOM)错误:
torch.OutOfMemoryError:CUDAoutofmemory.
Triedtoallocate1.90GiB.GPU0hasatotalcapacityof15.73GiBofwhich1.28GiBisfree.
Includingnon-PyTorchmemory,thisprocesshas14.43GiBmemoryinuse.Oftheallocatedmemory11.82GiBisallocatedbyPyTorch,and2.41GiBisreservedbyPyTorchbutunallocated.IfreservedbutunallocatedmemoryislargetrysettingPYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truetoavoidfragmentation.?SeedocumentationforMemoryManagement?()
实验结果与内存需求分析
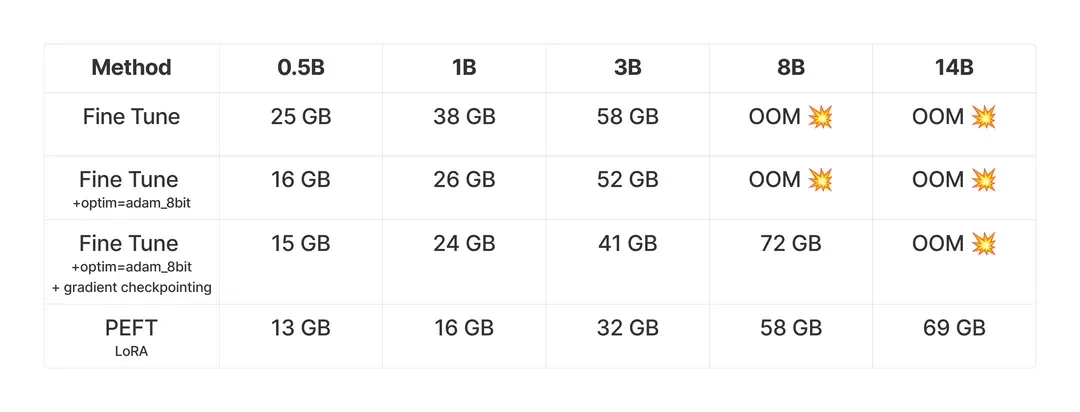
作者进行了一系列实验,测试不同模型大小(5亿到140亿参数)在GSM8K数据集上训练前100步的峰值内存使用情况,并比较了全参数微调和PEFT的内存需求。所有实验均在NVIDIAH100上完成。
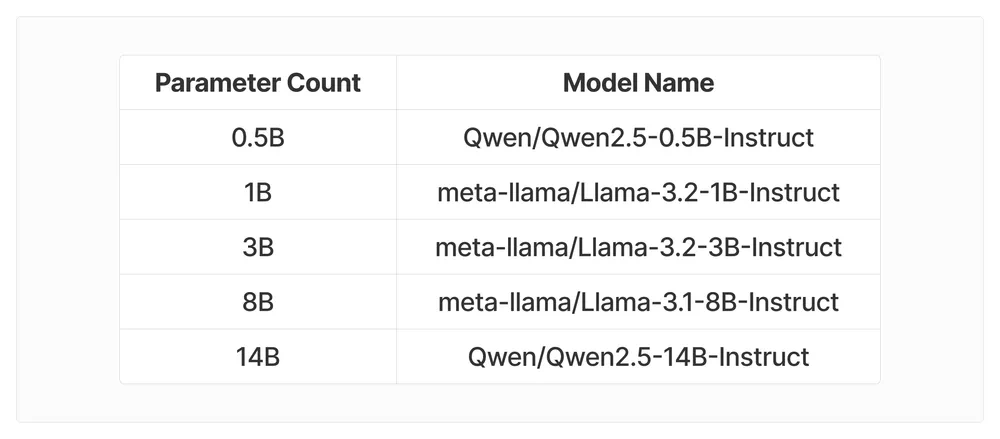
使用的模型包括:
GRPO对内存需求高的原因在于其内部涉及多个模型(策略模型、参考模型、奖励模型)以及每个查询产生的多个输出。
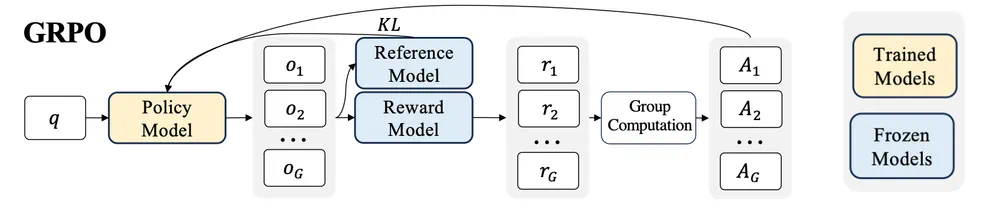
优化内存使用
8位优化器和梯度检查点技术可以有效减少内存占用。8位优化器更高效地存储优化器状态,而梯度检查点则通过在训练过程中拍摄快照来减少内存使用,虽然会降低训练速度。
代码示例
trl库简化了GRPO的使用。以下代码示例展示了如何使用trl训练小型模型:
importtorch
fromdatasetsimportload_dataset,Dataset
fromtransformersimportAutoTokenizer,AutoModelForCausalLM
fromtrlimportGRPOConfig,GRPOTrainer
importre
SYSTEM_PROMPT="""
Respondinthefollowingformat:
...
...
"""
defextract_hash_answer(text:str)->str|None:
if"####"notintext:
returnNone
returntext.split("####")[1].strip()
defget_gsm8k_questions(split="train")->Dataset:
data=load_dataset('openai/gsm8k','main')[split]
data=data.map(lambdax:{
'prompt':[
{'role':'system','content':SYSTEM_PROMPT},
{'role':'user','content':x['question']}
],
'answer':extract_hash_answer(x['answer'])
})
returndata
defextract_xml_answer(text:str)->str:
answer=text.split("
answer=answer.split("")[0]
returnanswer.strip()
defformat_reward_func(completions,**kwargs)->list[float]:
"""Rewardfunctionthatchecksifthecompletionhasaspecificformat."""
pattern=r"^
responses=[completion[0]["content"]forcompletionincompletions]
matches=[re.match(pattern,r)forrinresponses]
return[0.5ifmatchelse0.0formatchinmatches]
defaccuracy_reward_func(prompts,completions,answer,**kwargs)->list[float]:
"""Rewardfunctionthatextractstheanswerfromthexmltagsandcomparesittothecorrectanswer."""
responses=[completion[0]['content']forcompletionincompletions]
extracted_responses=[extract_xml_answer(r)forrinresponses]
return[2.0ifr==aelse0.0forr,ainzip(extracted_responses,answer)]
defmain():
dataset=get_gsm8k_questions()
model_name="meta-llama/Llama-3.2-1B-Instruct"
model=AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="Flash_attention_2",
device_map=None
).to("cuda")
tokenizer=AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token=tokenizer.eos_token
training_args=GRPOConfig(
output_dir="output",
learning_rate=5e-6,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_generations=4,
max_prompt_length=256,
max_completion_length=786,
num_train_epochs=1,
save_steps=100,
save_total_limit=1,
max_grad_norm=0.1,
log_on_each_node=False,
)
trainer=GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
format_reward_func,
accuracy_reward_func
],
args=training_args,
train_dataset=dataset,
)
trainer.train()
if__name__=="__main__":
main()
trl项目地址:
超参数调整与VRAM估算
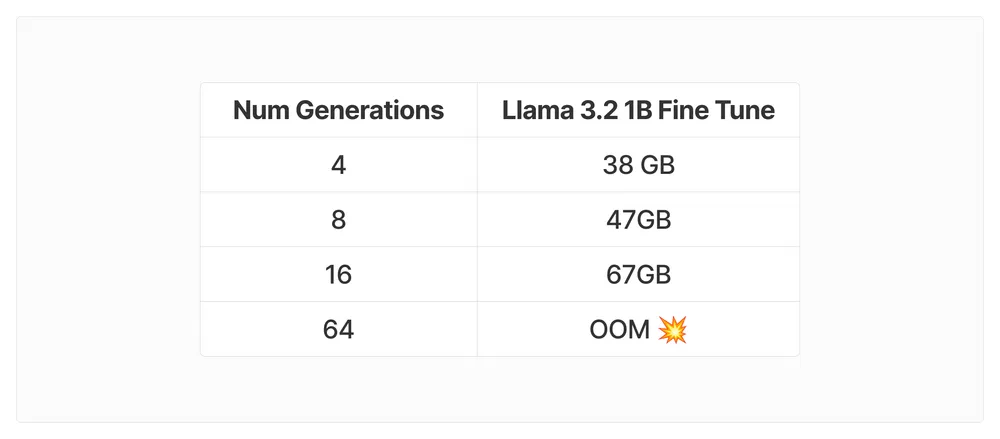
num_generations超参数会显著影响VRAM消耗。建议在内存瓶颈解决前使用num_generations=4。
GitHub问题讨论:
其他影响VRAM的因素包括batch_size、gradient_accumulation_steps、max_prompt_length、max_completion_length和LoRA的target_modules。
最后,作者分享了10亿参数Llama3.2模型的训练结果,展示了GRPO在提高模型准确率方面的潜力。
通过合理的参数设置和优化技术,即使使用资源有限的RTX3080移动版GPU,也能有效训练大型语言模型。
以上就是DeepSeek用的GRPO占用大量内存?有人给出了些破解方法的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 近期热点
近期热点













