在追求数据安全与自主控制的今天,将先进的语言模型如Ollama融入到我们的私有环境变得日益重要。Dify,作为一个灵活的平台,它的设计初衷就是为了无缝对接各种智能服务,而将Ollama本地部署模型与Dify平台整合,无疑是技术融合的一大步。这一集成不仅能够为企业的内部应用提供强大的自然语言处理能力,还确保了数据处理过程的隐私性和合规性。通过本篇指南,我们将深入探索如何在保持数据闭环的同时,充分利用Ollama的强大算法,打造专属的、高效且安全的智能对话系统,为企业智能化转型铺设坚实的基石。这一创新实践,标志着企业能够在不牺牲性能的前提下,完全掌控其人工智能解决方案的部署和管理,开启定制化AI服务的新篇章。
dify支持集成ollama部署的大型语言模型(llm)推理和嵌入能力。
快速集成指南下载并运行Ollama:请参考Ollama官方文档进行本地部署和配置。运行Ollama并启动Llama模型,例如:ollamarunllama3.1。成功启动后,Ollama会在本地11434端口启动API服务,访问地址为更多模型信息请访问
在Dify中配置Ollama:在Dify的“设置>模型供应商>Ollama”页面填写以下信息:
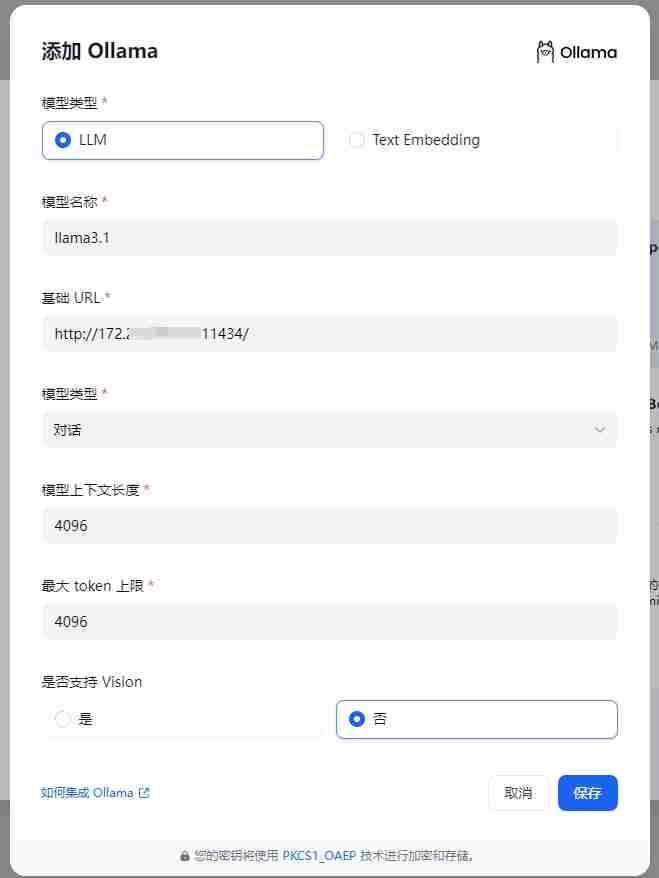
保存配置后,Dify将验证连接。
使用Ollama模型:在Dify应用的提示词编排页面选择Ollama供应商下的llama3.1模型,设置参数后即可使用。
常见问题解答(FAQ)??Docker部署下的连接错误:
如果您使用Docker部署Dify和Ollama,可能会遇到连接错误,例如Connectionrefused。这是因为Docker容器无法访问Ollama服务。解决方法是将Ollama服务暴露给网络,并使用正确的Ollama服务地址(例如Docker宿主机IP地址)在Dify中进行配置。
不同操作系统下的环境变量设置:
macOS:使用launchctlsetenvOLLAMA_host"0.0.0.0"设置环境变量,重启Ollama应用。如果无效,尝试使用host.docker.internal替换localhost。 Linux:使用systemctleditollama.service编辑systemd服务文件,添加Environment="OLLAMA_HOST=0.0.0.0",然后systemctldaemon-reload和systemctlrestartollama。 Windows:关闭Ollama,修改系统环境变量OLLAMA_HOST,然后重新启动Ollama。如何暴露Ollama服务:
Ollama默认绑定到127.0.0.1:11434。您可以通过设置OLLAMA_HOST环境变量将其绑定到0.0.0.0,使其在网络上可见。请注意网络安全,并仅在受信任的网络环境中这样做。
以上就是Ollama本地部署模型接入Dify的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略












