在数字时代的新篇章中,阿里巴巴前沿科技实验室隆重推出OmniSpeaker,这一革命性的技术框架彻底改变了人机交互的面貌。OmniSpeaker不仅是一个简单的文本到语音工具,它是一套先进的实时文本驱动的虚拟形象生成与交互系统,标志着个性化数字沟通进入了一个全新的纪元。通过高度定制化的头像与流畅自然的语言合成技术相结合,OmniSpeaker能够根据输入的文本内容,创造出栩栩如生的说话动画,赋予虚拟人物以生命,使得在线交流变得更加生动和贴近真实。这不仅为教育、娱乐、远程工作等多个领域提供了无限可能,也预示着未来数字沟通的无限广阔前景,开启了一扇通往更加沉浸式互动体验的大门。
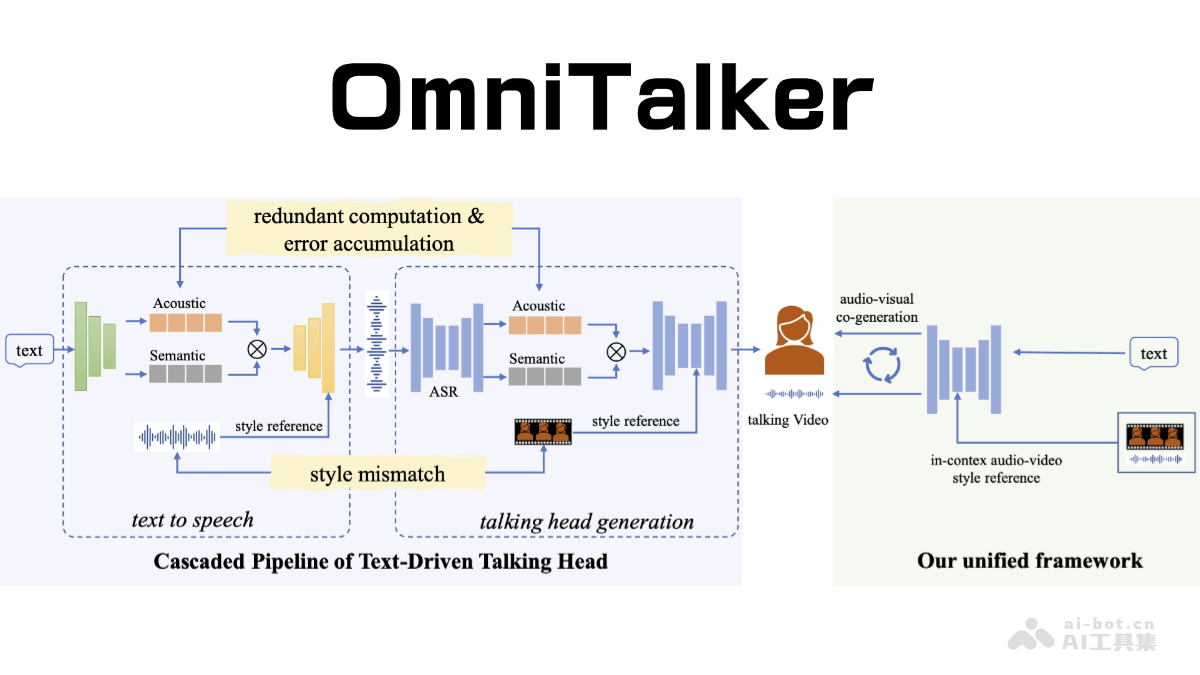
阿里巴巴推出的omnitalker,是一款基于实时文本驱动的说话头像生成技术。它能够流畅处理文本、图像、音频和视频等多种模态信息,并以流式方式生成自然逼真的语音回应。其核心架构为thinker-talker架构,thinker模块负责多模态输入的处理和语义理解,生成文本内容和高维语义表达;talker模块则将这些信息转化为流畅的语音输出。omnitalker采用tmrope技术,确保音视频输入的精准同步。
OmniTalker核心功能:
多模态信息融合:无缝整合文本、图像、音频和视频信息。 流式语音生成:实时生成自然流畅的语音和文本,采用分块处理方法,高效处理长序列数据。 精准音视频同步:TMRoPE技术确保音频和视频的完美同步。 实时交互能力:支持分块输入和即时输出,实现真正意义上的实时交互。 高品质语音输出:语音生成质量优异,超越众多同类技术。 卓越性能:在多模态基准测试中表现突出,音频能力优于同等规模的Qwen2-Audio,与Qwen2.5-VL-7B性能相当。技术原理详解:
OmniTalker基于创新的Thinker-Talker架构,Thinker模块利用Transformer解码器架构,并配备音频和图像编码器,负责多模态信息的提取和理解;Talker模块则采用双轨自回归Transformer解码器,直接利用Thinker模块生成的语义表征和文本,以流式方式生成语音token,从而保证语音输出的自然流畅。
为了解决音视频同步问题,OmniTalker引入了TMRoPE(时间对齐多模态旋转位置嵌入)技术,通过时间顺序交错排列音频和视频帧,并进行位置编码,实现不同模态信息在时间轴上的无缝衔接。
此外,OmniTalker采用流式处理方式,包括分块预填充(音频编码器采用2秒块式注意力机制,视觉编码器采用Flashattention并增加MLP层)和滑动窗口DiT模型(用于流式生成mel频谱图),从而提高效率并降低延迟。Thinker和Talker模块采用端到端联合训练,共享历史上下文信息,确保模型整体性能和一致性。高效的语音编解码器(qwen-tts-tokenizer)进一步提升了语音生成的自然度和鲁棒性。
项目信息:
项目官网: arXiv论文:应用前景:
OmniTalker的应用场景广泛,包括:智能语音助手、多模态内容创作、教育培训、智能客服以及工业质检等领域。其强大的多模态处理能力和高质量语音生成能力,将为各行各业带来全新的交互体验和效率提升。
以上就是OmniTalker—阿里推出的实时文本驱动说话头像生成框架的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略












