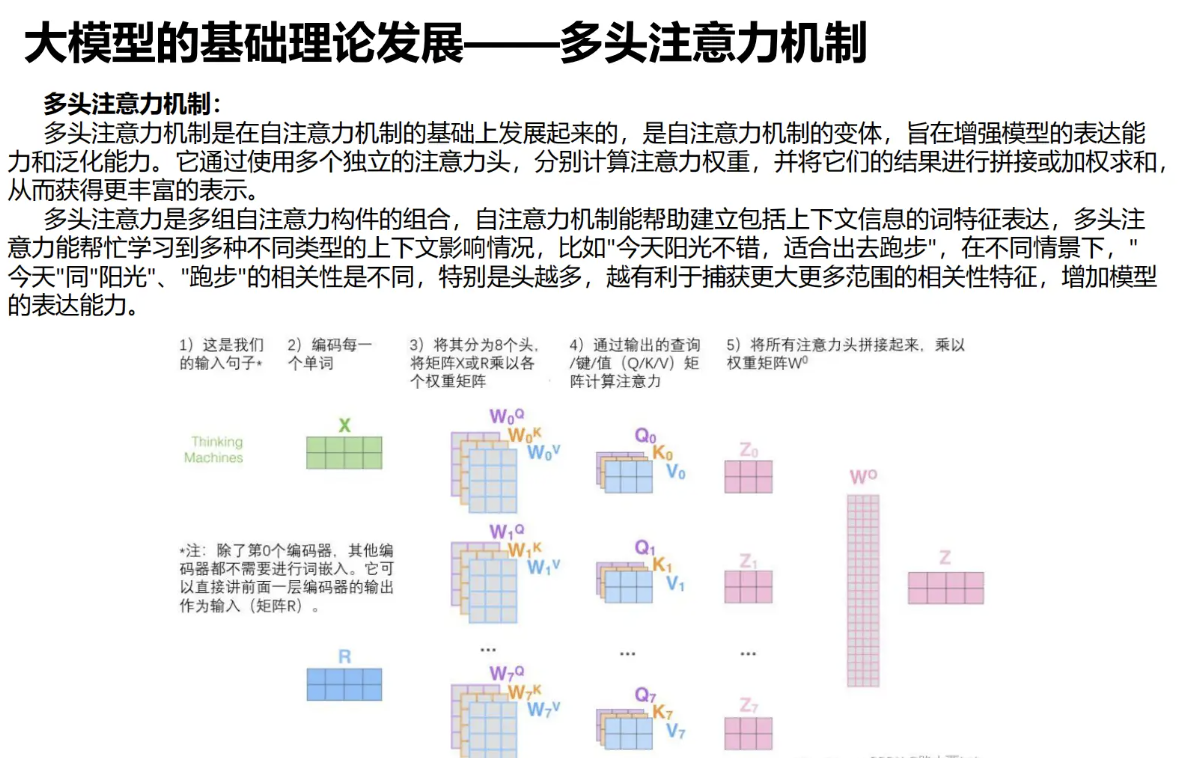
Transformer架构,自问世以来,便在自然语言处理领域掀起了一场革命。这一创新模型以其独特的注意力机制为核心,彻底改变了序列到序列学习的格局。它让机器能够更加智能地理解文本,跨越长距离依赖问题,展现出了前所未有的翻译准确性与并行处理能力,从而在诸如机器翻译、文本生成、问答系统等任务中大放异彩。然而,每一项技术的进步都伴随着其特有的挑战,Transformer也不例外。它对计算资源的高需求、训练时间的漫长以及在某些特定场景下的过拟合问题,成为了限制其更广泛应用的瓶颈。本文将深入探讨Transformer的这些鲜明特点,旨在为读者提供一个全面理解这一强大工具的视角,同时也揭示未来研究可能的改进方向。
Transformer架构基于自注意力机制,在多领域广泛应用。优点是高效处理长序列、并行计算强、自注意力灵活且扩展性佳。缺点为计算资源消耗大,对小规模数据不友好,还缺乏对序列顺序的显式建模,在特定场景需额外优化。
Transformer架构是一种基于自注意力机制的深度学习架构,在自然语言处理、计算机视觉等领域
得到了广泛应用。以下是其优点和缺点: 优点 高效处理长序列数据:传统的循环神经网络(RNN)和卷积神经网络(CNN)在处理长序列数据时,存在信息传递和长期依赖问题。而Transformer通过自注意力机制,可以直接对序列中的任意位置进行建模,能够有效地捕捉长序列中的依赖关系,无论距离多远,都能直接计算出相互之间的关联,从而更好地处理长序列数据。 并行计算能力强:Transformer架构可以并行计算,大大提高了训练和
推理的效率。它不需要像RNN那样顺序地处理每个时间步,而是可以同时对整个序列进行操作,能够充分利用现代硬件设备(如GPU、TPU)的并行计算能力,加快模型的训练速度,节省大量的时间和计算资源。 自注意力机制灵活:自注意力机制可以自动学习文本中的语义结构和语法关系,自适应地关注输入序列中的不同部分,对于不同的任务和数据能够动态地调整注意力权重,从而更好地理解文本的语义信息。相比之下,传统的CNN和RNN需要通过人为
设计的卷积核或循环结构来捕捉特征,灵活性较差。 可扩展性好:Transformer架构具有良好的可扩展性,可以方便地增加模型的层数、神经元数量或头的数量等,以提高模型的性能。随着数据量和计算资源的增加,Transformer能够通过增加模型规模来更好地拟合数据,从而在大规模数据集上取得显著的性能提升,适用于训练大规模的语言模型。 缺点 计算资源消耗大:Transformer在训练和推理过程中需要大量的计算资源,尤其是在处理长序列数据或大规模模型时,
内存占用和计算量会显著增加。这是因为自注意力机制需要计算序列中每个位置与其他位置的相似度,其时间复杂度和空间复杂度相对较高。因此,训练和部署Transformer模型通常需要强大的GPU或TPU等专用硬件设备,增加了计算成本和部署难度。 对小规模数据不友好:由于Transformer模型规模较大,需要大量的数据来进行训练才能充分发挥其性能优势。在小规模数据集上,Transformer容易出现过拟合现象,即模型在训练集上表现良好,但在测试集或新数据上的泛化能力较差。这是因为模型过于复杂,容易记住训练数据中的噪声和细节,而无法学习到数据的一般性规律。 缺乏对序列顺序的显式建模:虽然Transformer能够通过自注意力机制捕捉序列中的依赖关系,但它并没有显式地对序列的顺序信息进行建模。相比之下,RNN等架构通过循环结构可以自然地处理序列的顺序信息。在一些对顺序敏感的任务中,如
语音识别中的时间序列建模、文本生成中的上下文连贯性等,Transformer可能需要额外的机制来更好地利用顺序信息。
以上就是Transformer架构的优点和缺点分别是什么的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略












