在人工智能的浩瀚宇宙中,一场无声的智力竞赛正在上演。近日,一个令人瞩目的成就震撼了AI界——经过深邃的思考与优化,一个仅3B参数的模型成功超越了其70B参数的庞然大物,这一事件不仅颠覆了业界对模型大小与性能关系的传统认知,更彰显了智能设计的精妙所在。在这场智慧的博弈背后,HuggingFace扮演了关键角色,它不仅深入剖析了这场胜利的技术秘诀,还慷慨地将核心细节公开于世,开启了技术共享的新篇章。此次开源之举,不仅让学术界和开发者们得以窥见高效模型设计的奥秘,更是推动了AI领域向更加开放、协作的方向迈进。随着o1技术的面纱被缓缓揭开,我们不禁好奇,这背后的架构设计与优化策略如何实现了以小博大的奇迹,又将如何塑造未来AI发展的新趋势。
大幅提升小模型性能:huggingface开源deepmind技术,1b参数模型超越70b模型!
近期,业界对小模型的关注度空前高涨,许多“实用技巧”让小模型性能超越了更大规模的模型。这种趋势源于大模型训练成本的急剧增加,动辄数十亿美元的集群投入使得探索更经济高效的方案成为必然。
因此,“测试时计算扩展”(test-TIMecomputescaling)应运而生。该方法并非依赖于扩大预训练规模,而是通过动态推理策略,让模型在复杂问题上“思考更久”。OpenAI的o1模型就是一个典型案例,其在困难的数学问题上,性能随着测试时计算量的增加而持续提升。
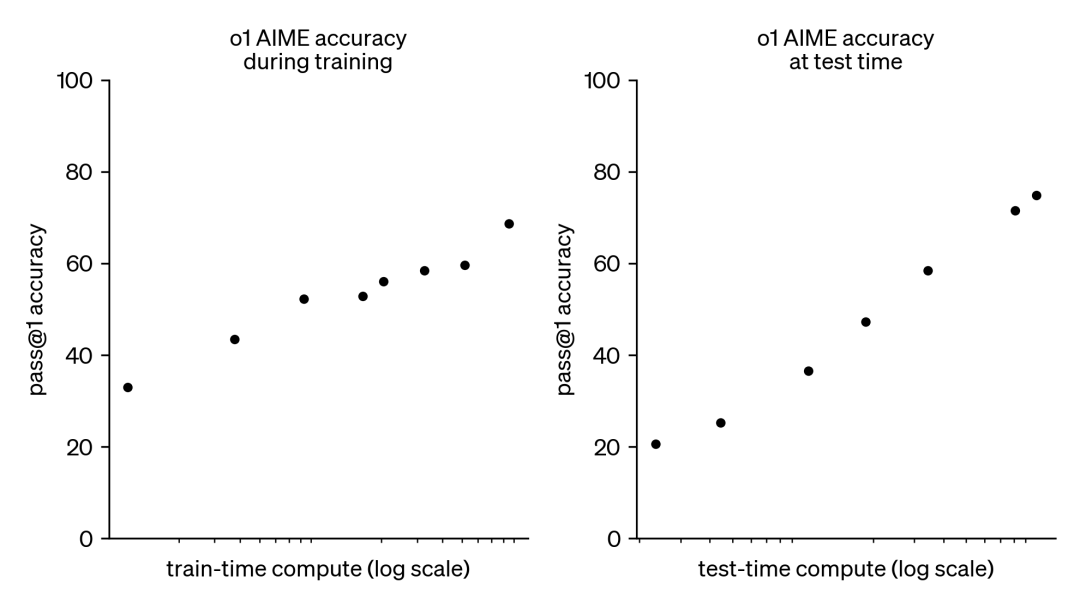
虽然o1的训练细节未公开,但DeepMind的研究表明,迭代自我改进或基于奖励模型的解决方案空间搜索等策略,能够实现测试时计算的最佳扩展。通过自适应地分配测试时计算资源,小模型可以与大型模型性能相当,甚至超越后者。尤其在内存受限、硬件资源不足的情况下,这种方法更具优势。然而,DeepMind的研究结果主要基于闭源模型,缺乏实现细节和代码公开。
DeepMind论文:
HuggingFace积极跟进DeepMind的研究,并取得了显著成果。他们开源了相关技术,主要包括:
计算最优扩展(compute-optimalscaling):通过复现DeepMind的技术,提升开放模型的数学能力。 多样性验证器树搜索(DVTS):验证器引导树搜索技术的扩展,提升多样性,尤其在测试时计算预算较大时性能更佳。 搜索和学习:一个轻量级工具包,用于实现基于LLM的搜索策略,并利用vLLM加速。实验结果令人振奋:在MATH-500基准测试中,给予足够“思考时间”,1B和3B参数的LlamaInstruct模型,性能超越了8B和70B参数的模型。

HuggingFace联合创始人兼CEOClemDelangue表示,仅在OpenAIo1发布十天后,他们就开源了其核心技术的复现版本,证明了通过延长模型“思考时间”,小模型也能战胜大型模型。



测试时计算扩展策略
主要策略包括:
自我改进:模型迭代改进自身输出,但需模型具备自我改进机制,适用性受限。 基于验证器的搜索:生成多个候选答案,用验证器选择最佳答案。验证器可以是硬编码启发式方法或学习型奖励模型。本文重点介绍学习型奖励模型,包括Best-of-N采样和树搜索等技术。HuggingFace专注于基于搜索的方法,主要包括:

实验设置及结果
实验使用meta-llama/Llama-3.2-1B-Instruct模型,RLHFlow/Llama3.1-8B-PRM-Deepseek-Data作为PRM,以及MATH-500数据集。
结果显示,集束搜索在计算效率上显著优于Best-of-N和多数投票,性能与Llama3.18B模型相当。DVTS则在较大计算预算下表现更佳,提升了简单/中等难度问题的性能。计算最优扩展策略则在3B参数模型上取得了超越70B模型的惊人效果。



未来方向
未来研究方向包括:提升验证器性能,实现模型自我验证,将思维融入生成过程,利用搜索生成高质量训练数据,以及开发更多领域的PRM。
原文链接:
以上就是3B模型长思考后击败70B!HuggingFace逆向出o1背后技术细节并开源的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 近期热点
近期热点 最新攻略
最新攻略












