在数字音频的浩瀚宇宙中,PlayDiffusion犹如一位革新者,它不仅仅是技术的里程碑,更是创意与智能融合的结晶。这款由开源社区热情浇筑的音频编辑模型,正悄然改变着我们对声音设计的理解和实践。PlayDiffusion解锁了音频编辑的新维度,它利用先进的人工智能算法,赋予用户前所未有的能力,能够精细地创作、编辑乃至重塑声音景观。从细腻的音色调整到复杂的音频合成,每一刻都彰显着AI技术与艺术创作的完美邂逅。这不仅仅是一个工具的发布,更是一场音频制作领域的革命,它降低了专业音频处理的门槛,让创意的火花在每一个热爱声音的人手中自由绽放。随着PlayDiffusion的开源,一场属于每个人的音频创意风暴,正蓄势待发。
PlayDiffusion是什么
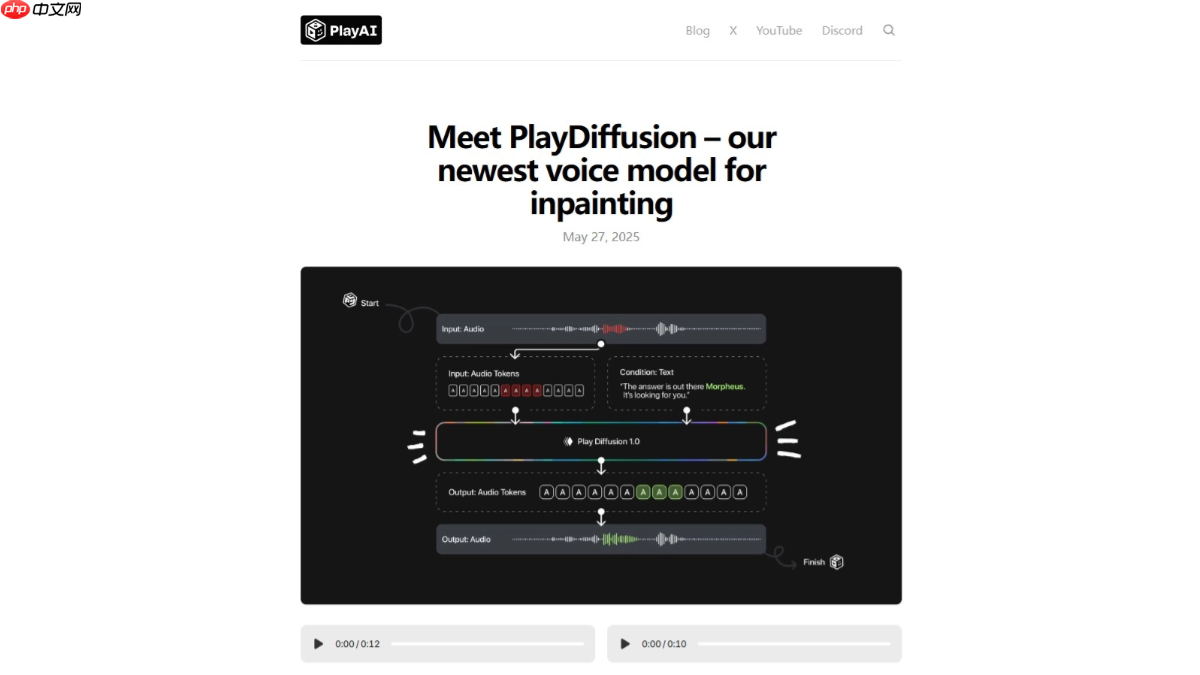
playdiffusion是playai推出的新型音频编辑模型,基于扩散模型技术,专门用在音频的精细编辑和修复。模型将音频编码为离散的标记序列,对需要修改的部分进行掩码处理,用扩散模型在给定更新文本的条件下对掩码区域进行去噪,实现高质量的音频编辑。模型能无缝保留上下文,确保语音的连贯性和自然性,同时支持高效的文本到语音合成。playdiffusion的非自回归特性在生成速度和质量上优于传统的自回归模型,为音频编辑和语音合成领域带来新的突破。
PlayDiffusion的主要功能
音频局部编辑:支持对音频进行局部替换、修改或删除,无需重生成整段音频,保持语音自然、无缝衔接。 高效TTS:在掩码整个音频时,作为高效TTS模型,
推理速度比传统TTS提高50倍,语音自然度和一致性更优。 保持语音连贯性:编辑时保留上下文,确保语音连贯性和说话者音色一致。 动态语音修改:根据新文本自动调整语音发音、语气和节奏,适用实时互动等场景。 无缝集成与易用性:支持HuggingFace集成和本地部署,方便快速体验和使用。
PlayDiffusion的技术原理
音频编码:将输入的音频序列编码为离散的标记序列,每个标记代表音频的一个单元。适用于真实语音和由文本到语音模型生成的音频。 掩码处理:当需要修改音频的某个部分时,将该部分标记为掩码,便于后续处理。 扩散模型去噪:基于更新文本的扩散模型对掩码区域进行去噪。扩散模型基于逐步去除噪声,生成高质量的音频标记序列。用非自回归方法,同时生成所有标记基于固定数量的去噪步骤进行细化。 解码为音频波形:将生成的标记序列基于BigVGAN解码器模型转换回语音波形,确保最终输出的语音自然且连贯。
PlayDiffusion的项目地址
项目官网:
GitHub仓库: 在线体验Demo:
PlayDiffusion的应用场景
配音纠错:快速替换错误发音,保持配音自然流畅。 合成对话改词:轻松修改对话内容,确保语言准确自然。 播客
剪辑:修改或删除片段,提升内容质量。 实时语音互动:动态调整语音内容,实现自然交互。 语音合成:高效生成高质量语音,适用于播报等场景。
以上就是PlayDiffusion—PlayAI开源的音频编辑模型的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略













