在人工智能领域的一次重大突破中,Agentica公司与Together AI强强联合,共同揭开了DeepCoder-14B-Preview的神秘面纱。这款前沿的开源代码生成模型,标志着编程自动化迈入了一个全新的阶段。DeepCoder-14B-Preview,以其庞大的140亿参数量,成为了程序员和开发者们梦寐以求的工具。它不仅能够自动生成高效、准确的代码片段,还旨在通过开源的方式,促进全球技术社区的创新交流,降低软件开发的门槛。这款模型的问世,预示着未来软件开发将更加注重效率与创造力的结合,为AI辅助编程领域树立了新的标杆。随着DeepCoder-14B-Preview的开源,我们期待见证无数创新项目在这一强大工具的助力下应运而生,共同推动技术界的革新浪潮。
deepcoder-14b-preview:一款开源的140亿参数代码生成模型
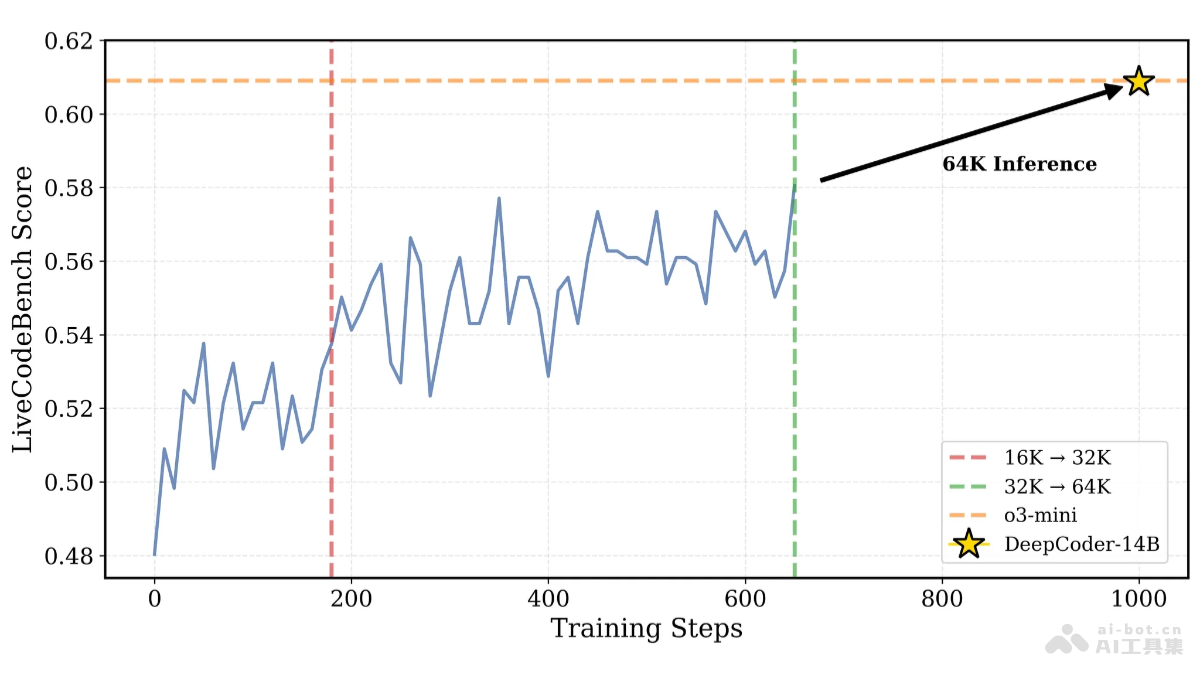
Agentica和TogetherAI联合发布了DeepCoder-14B-Preview,这是一个基于Deepseek-R1-Distilled-Qwen-14B微调的大型代码生成模型。该模型采用分布式强化学习(RL)训练,在代码生成任务上表现优异,尤其在LiveCodeBench基准测试中取得了60.6%的准确率,与OpenAI的o3-mini模型不相上下。更重要的是,其训练数据集、代码、训练日志和系统优化方案均已开源,旨在降低RL训练门槛,促进社区发展和强化学习在大型语言模型(LLM)领域的应用。
核心功能:
高效代码生成:生成高质量、可执行的代码,支持多种编程语言和应用场景。 代码问题解决:协助解决复杂的编程难题,包括算法设计和数据结构优化等。 代码补全与优化:提供代码自动补全,提升编码效率,并优化现有代码。 单元测试生成:自动生成单元测试代码,确保代码的准确性和可靠性。 代码调试辅助:帮助开发者快速定位和修复代码错误。 跨平台兼容:支持多种编程环境和平台。技术架构:
DeepCoder-14B-Preview基于经过蒸馏优化的140亿参数预训练模型Deepseek-R1-Distilled-Qwen-14B,并通过分布式强化学习进行微调。其训练使用了24000个经过严格筛选的可验证编程问题,数据来源包括TACOVerified、PrimeIntellect的SYNTHETIC-1数据集以及LiveCodeBench。模型采用稀疏结果奖励模型(ORM),仅在生成的代码通过所有采样单元测试时才给予奖励,避免模型依赖记忆测试用例。此外,迭代上下文扩展技术和verl-pipeline流水线技术分别提升了模型的泛化能力和训练效率。
项目资源:
项目主页: HuggingFace模型库:应用场景:
代码自动化:加速代码编写,提高开发效率。 算法竞赛:辅助算法竞赛选手快速解决问题。 代码优化与重构:提升代码质量和可维护性。 编程教育:作为编程学习和教学辅助工具。 软件开发与测试:辅助软件开发和测试流程。以上就是DeepCoder-14B-Preview—Agentica联合TogetherAI开源的代码生成模型的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略













