在人工智能的浩瀚宇宙中,阿里云的精英科学家们揭开了一道通往智慧极限的神秘面纱。《混元专家之谜:平衡之光》是一部关于智者探索与突破的科技传奇。在这片数字的海洋里,混合专家模型(MoE)犹如众神之域,每个专家都是知识的守护者,却受限于“局部负载均衡”的古老魔咒,导致力量分布不均,智慧之光暗淡。
主角,一位来自未来的算法探险家,携带着创新的“全局负载均衡”秘法,穿梭在由亿万个数据片段构成的迷宫中。他们面临的挑战,是让被遗忘的专家重获新生,让模型的潜力如星辰般璀璨。通过一场场与数据多样性的舞蹈,他们巧妙地同步专家间的激活频率,如同编织一场精妙绝伦的数据交响乐。
在技术的光辉下,每一次计算都是一次对未知的叩问,每一次优化都仿佛是解开宇宙秘密的钥匙。《混元专家之谜》不仅是一场技术的革命,更是对智慧极限的无尽追求。在这场知识的盛宴中,阿里云的科学家们以人类智慧之名,书写着连接过去与未来,局部与全局的壮丽篇章。
阿里云通义千问团队在最新论文中揭示了混合专家模型(moe)训练中的一个关键问题,并提出了一种创新的解决方案。该问题在于现有moe训练框架普遍采用局部负载均衡损失(lbl),导致专家激活不均衡,限制了模型性能和专家特异性。

该团队提出的方法通过轻量级通信机制,将局部负载均衡提升为全局负载均衡。这使得模型能够更好地利用数据多样性,从而提高专家特异化程度和整体模型性能。
 -论文:《DemonsintheDetail:OnImplementingLoadBalancingLossforTrainingSpecializedMixture-of-ExpertModels》
-论文:《DemonsintheDetail:OnImplementingLoadBalancingLossforTrainingSpecializedMixture-of-ExpertModels》
MoE训练中的挑战与解决方案
MoE通过路由机制动态激活模型参数,提升了模型容量。然而,基于TopK的稀疏激活容易导致专家激活不均衡,少数专家被过度利用,其余专家资源浪费。为此,通常引入LBL来平衡专家激活。
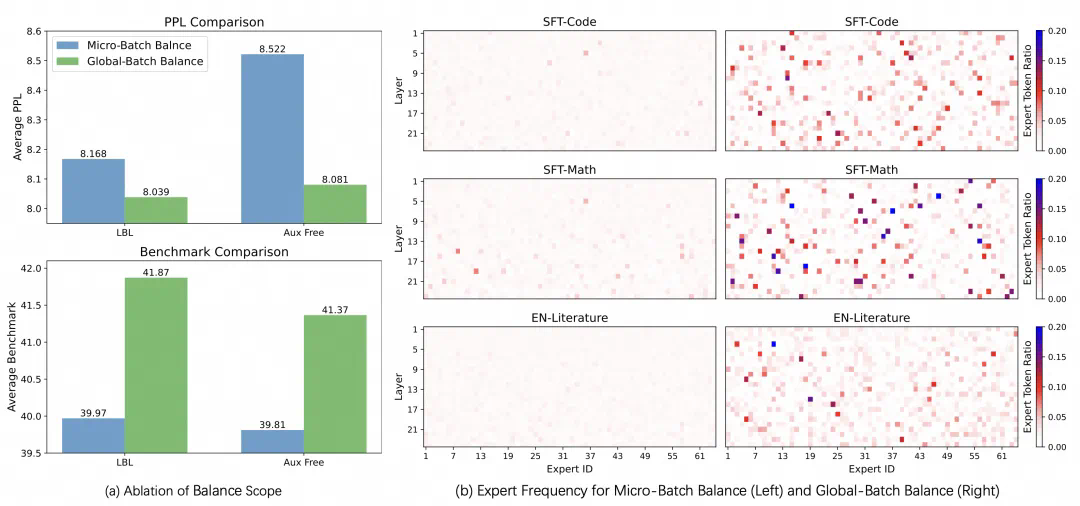
现有框架的LBL通常在局部(mini-batch)层面计算,这在mini-batch数据缺乏多样性时会限制专家特异化。阿里云团队的方案通过跨mini-batch同步专家激活频率,实现全局LBL计算,有效解决了这个问题。
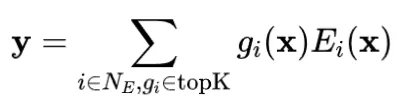
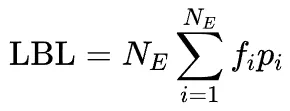
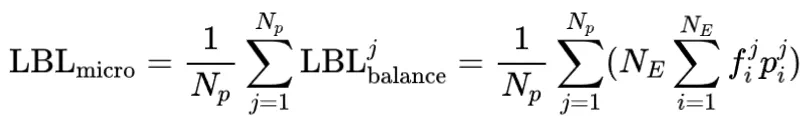
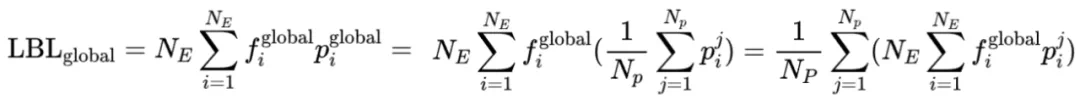
实验结果表明,该方法显著提升了模型性能和专家特异性,尤其是在大规模模型训练中效果明显。此外,研究还发现,添加少量局部LBL可以进一步提高训练效率,而不会显著影响模型性能。
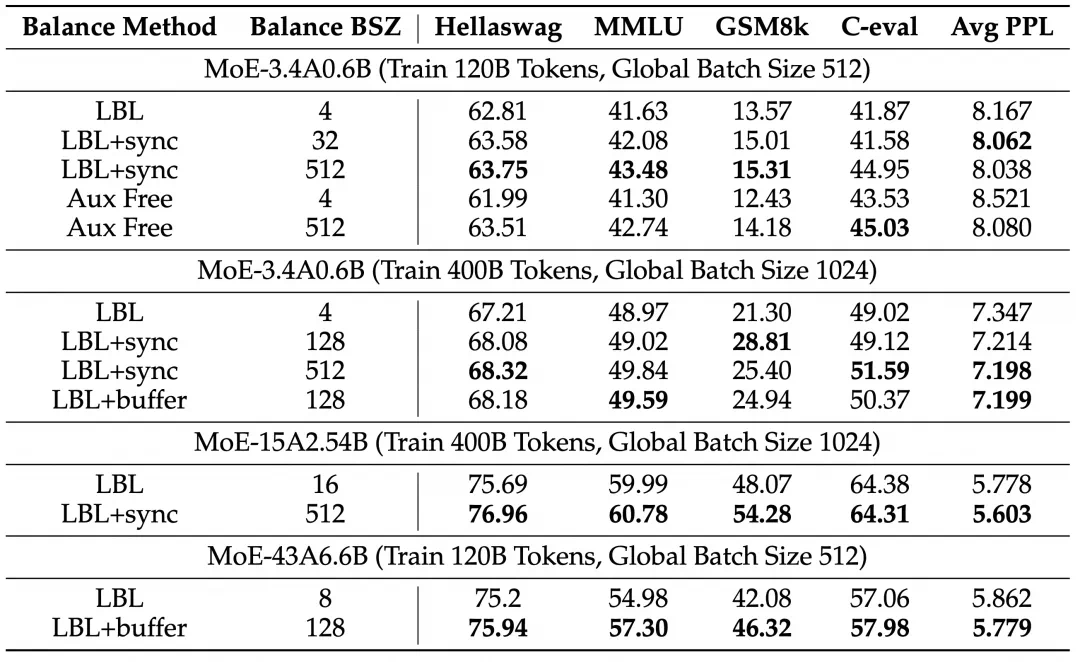
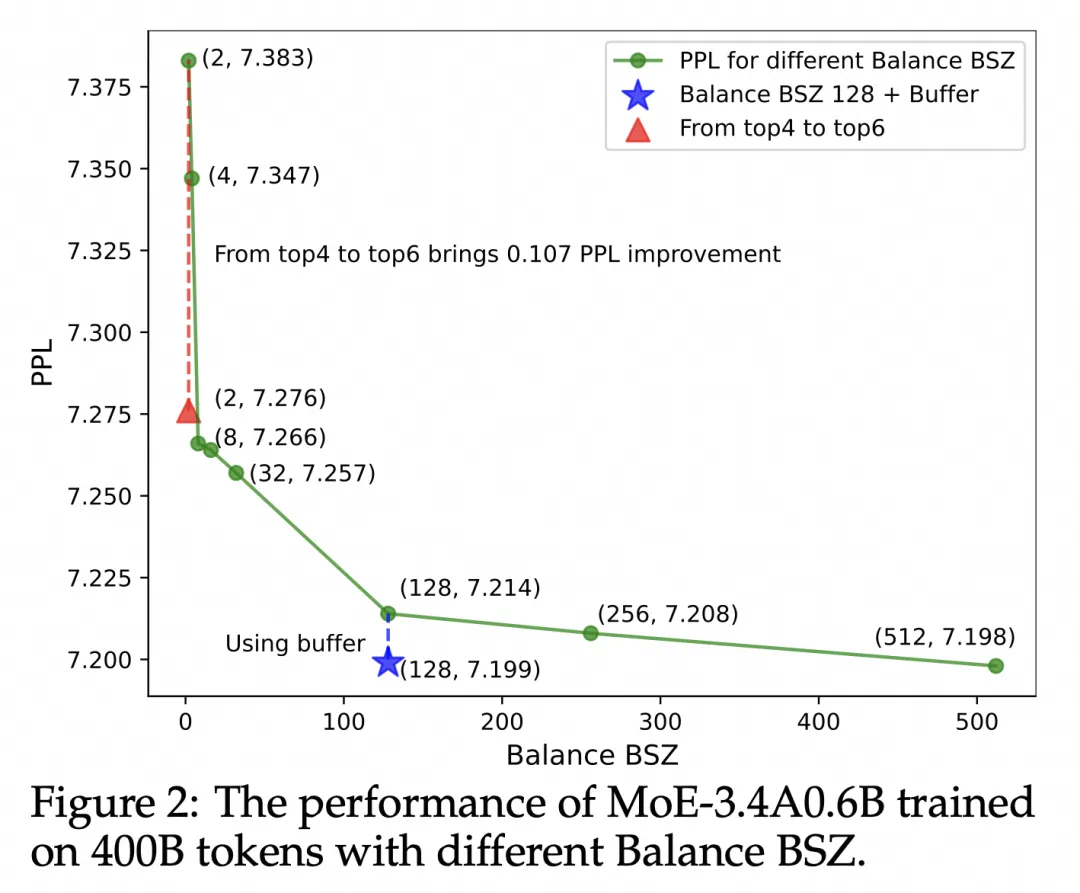
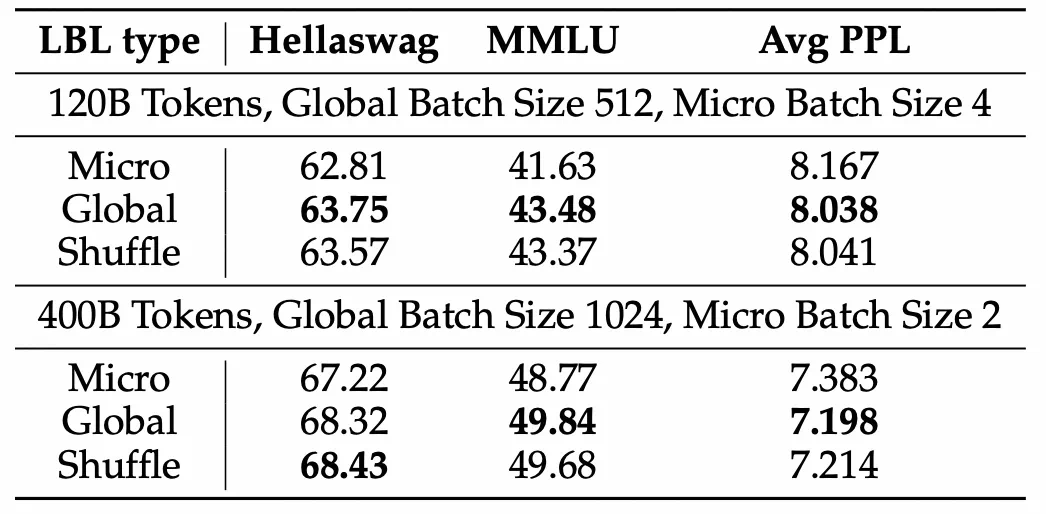
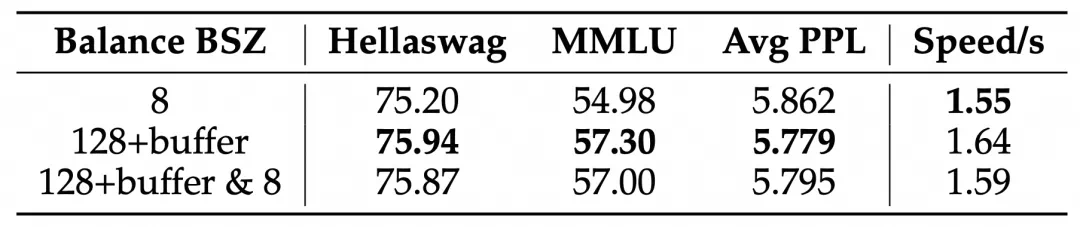
这项研究为MoE模型的训练提供了新的思路,有助于构建更高效、更可解释的大规模模型。虽然实验主要集中在语言模型领域,但其方法具有广泛的应用前景。
以上就是阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略




