在人工智能的浩瀚领域中,一场视觉与语言的深度交融正悄然拉开序幕——欢迎进入Florence-VL的时代。这不仅仅是一个技术名词的简单登场,它代表着一次革命性的突破,将生成式视觉编码器的精妙融入到多模态大语言模型的核心之中。Florence-VL,这个名字背后蕴藏着对传统界限的跨越,它不再让语言孤立于文字之中,而是让它能够理解和生成视觉内容,如同拥有了洞察世界的眼睛。通过这一创新,模型不仅能够理解和回答基于文本的问题,还能处理和生成图像信息,开启了人机交互的新纪元。我们正站在一个多模态智能新时代的门槛上,Florence-VL以其前所未有的能力,预示着未来AI将如何更加自然、全面地理解与表达这个世界。
Florence-VL:基于生成式视觉编码器的多模态大语言模型
马里兰大学与微软研究院合作推出了一种新型多模态大语言模型Florence-VL,该模型利用生成式视觉编码器Florence-2,显著提升了对图像中细节信息的理解能力。这项研究由马里兰大学博士生陈玖海领衔,BinXiao担任通讯作者,并由马里兰大学助理教授TianyiZhou以及微软研究院研究员JianweiYang,HaipingWu,JianfengGao共同完成。

资源链接:
论文: 开源代码: 项目主页: 在线Demo: 模型下载:Florence-VL的核心在于采用Florence-2作为视觉编码器。不同于传统的CLIP等模型仅提供单一全局图像表示,Florence-2通过生成式预训练,能够根据不同的任务提示生成多样化的视觉特征,从而更全面地理解图像细节,包括局部信息和像素级信息。Florence-VL巧妙地利用多个任务提示(例如图像描述、OCR和物体定位),并融合不同深度层的特征,实现了更强大的视觉理解能力。
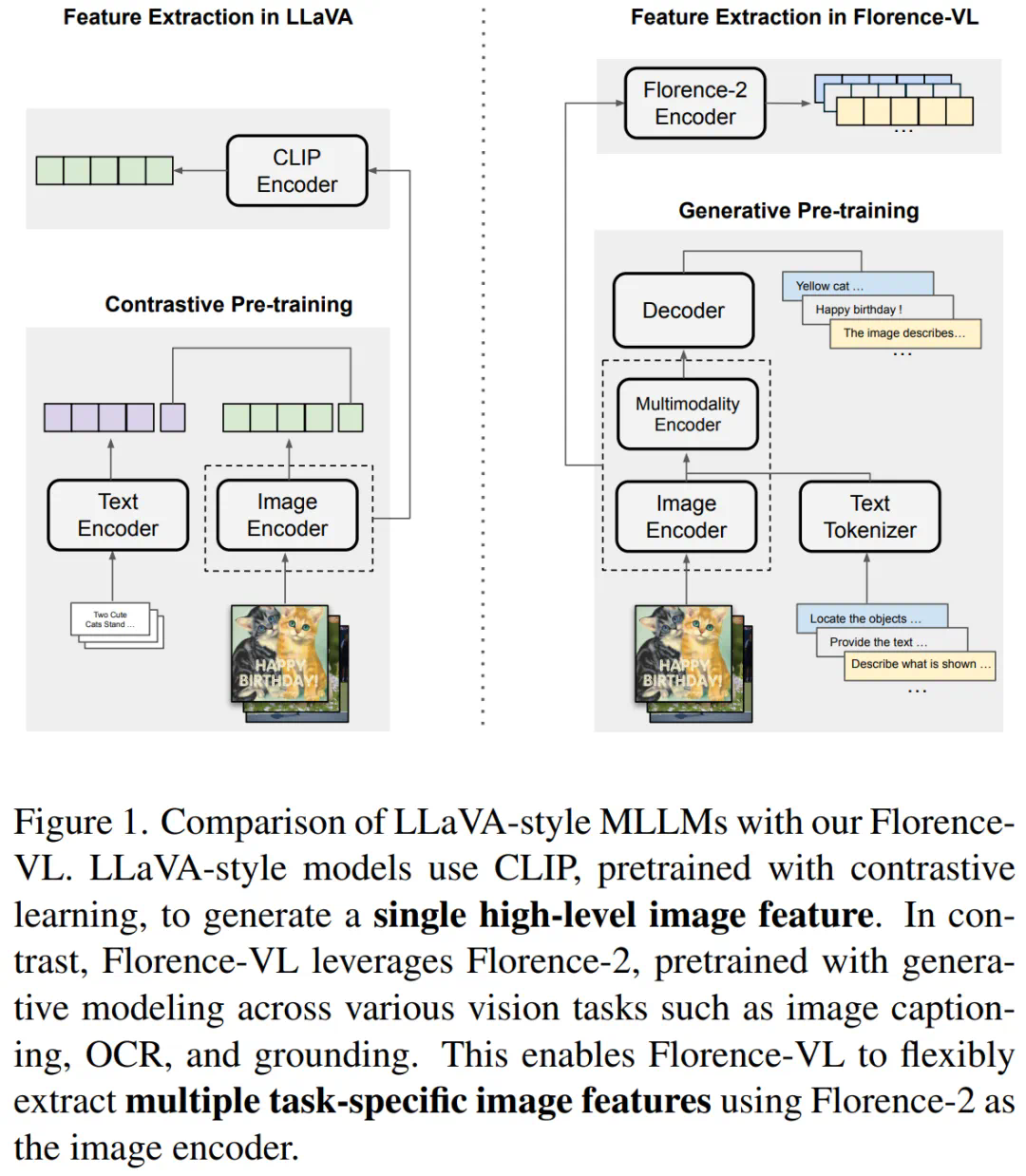
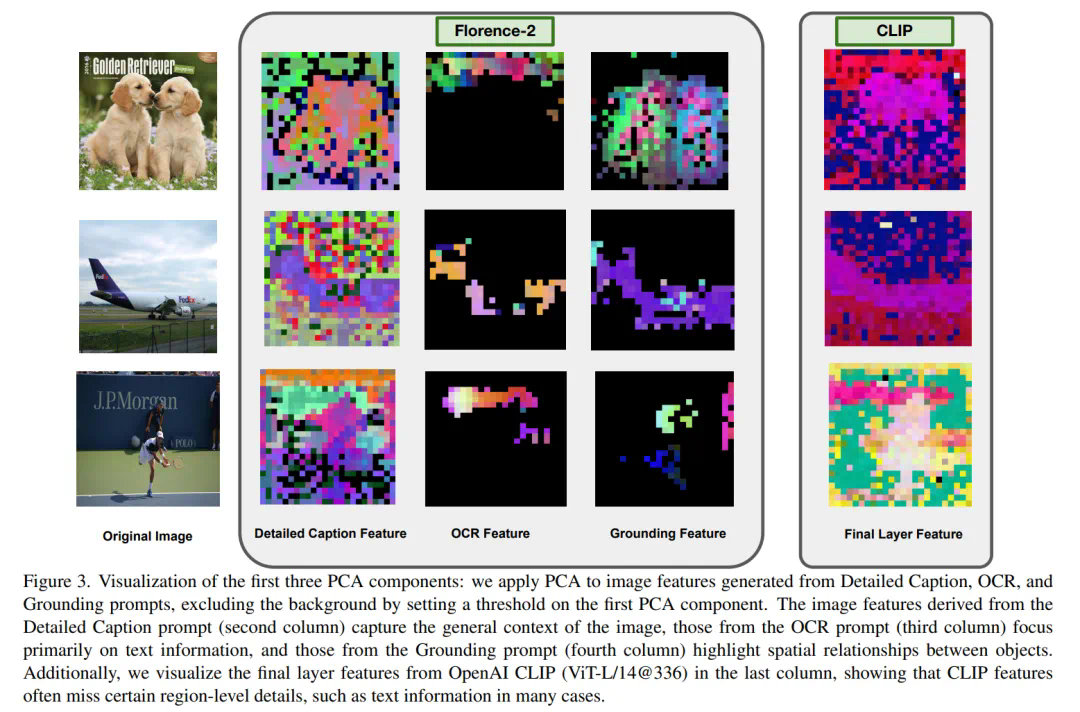
核心技术:深度-广度融合策略(DBFusion)
Florence-VL的创新之处在于其深度-广度融合策略,它有效地结合了多任务提示和多层级特征,以获得更丰富的视觉表征:
广度:通过不同的任务提示(例如图像描述、OCR和物体定位),生成针对不同任务的视觉特征。 深度:利用Florence-2不同深度层捕获从低级到高级的视觉特征,实现对细节和整体信息的兼顾。 融合:采用通道拼接策略,将不同任务和不同深度层的特征高效整合,避免增加模型计算负担,同时保留特征的多样性。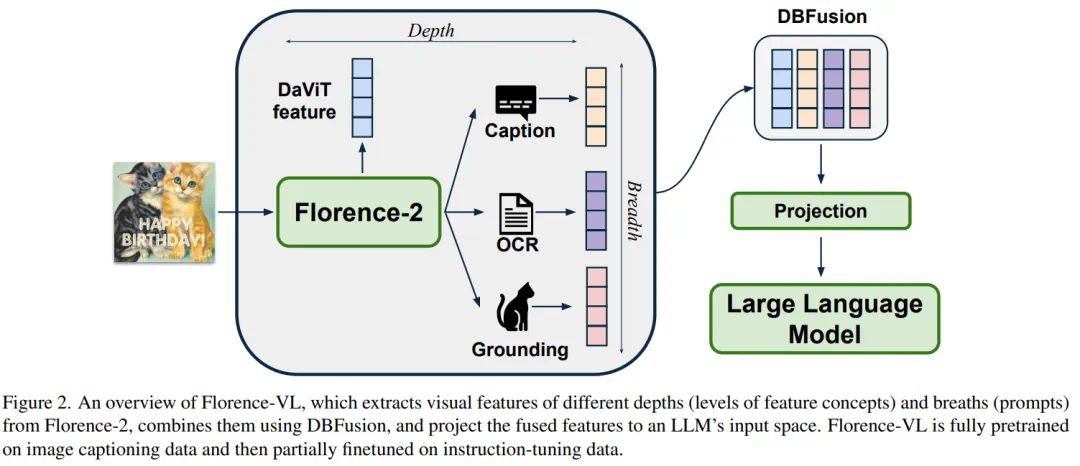
实验结果与对比
研究团队通过一系列实验,在多个多模态基准任务上评估了Florence-VL的性能,包括通用视觉问答、OCR、知识理解等。结果显示,Florence-VL在多个任务上超越了基于CLIP等传统视觉编码器的模型,尤其在文本提取任务上表现突出。消融实验也证明了Florence-2作为视觉编码器的优越性。
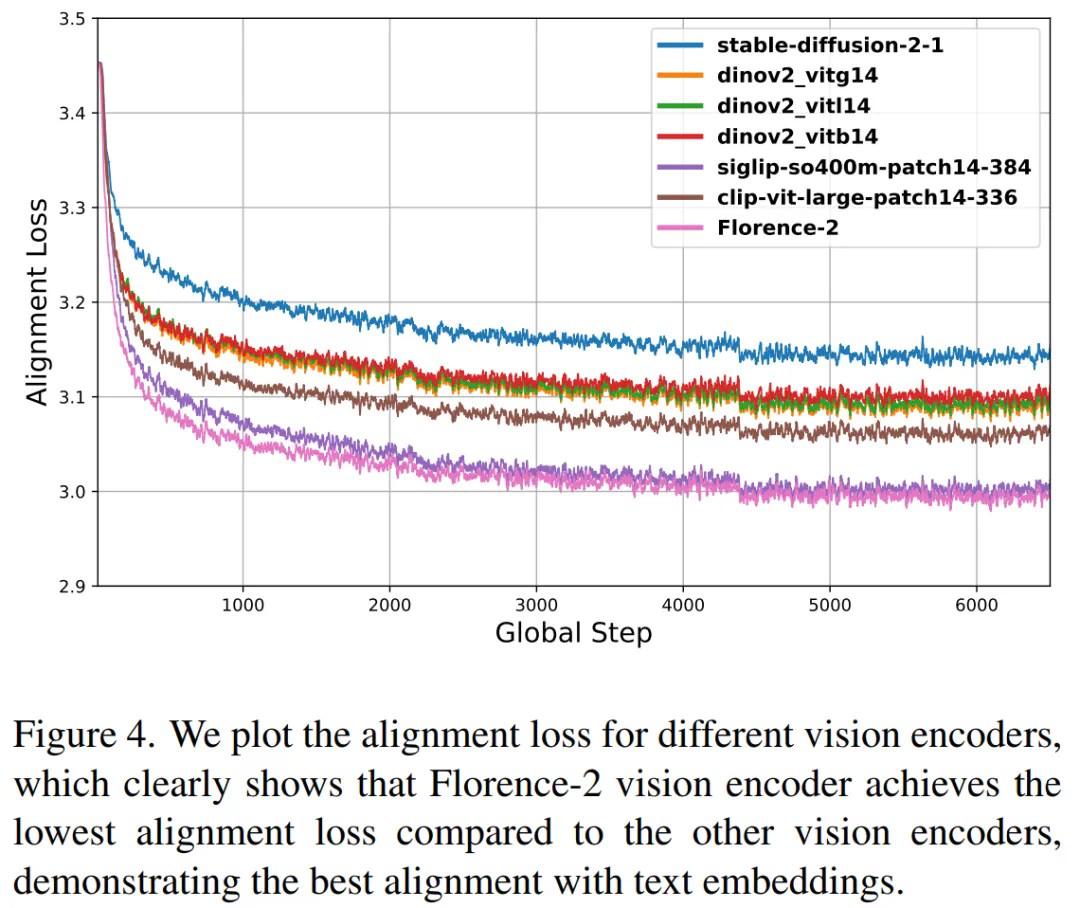
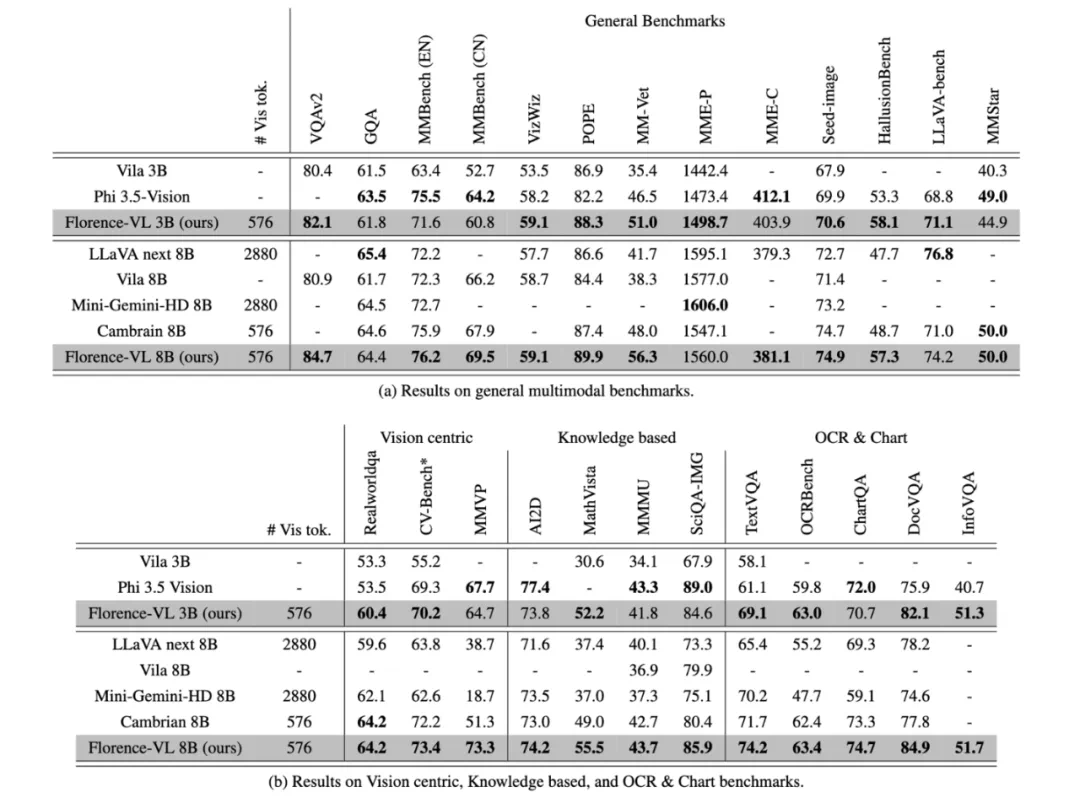
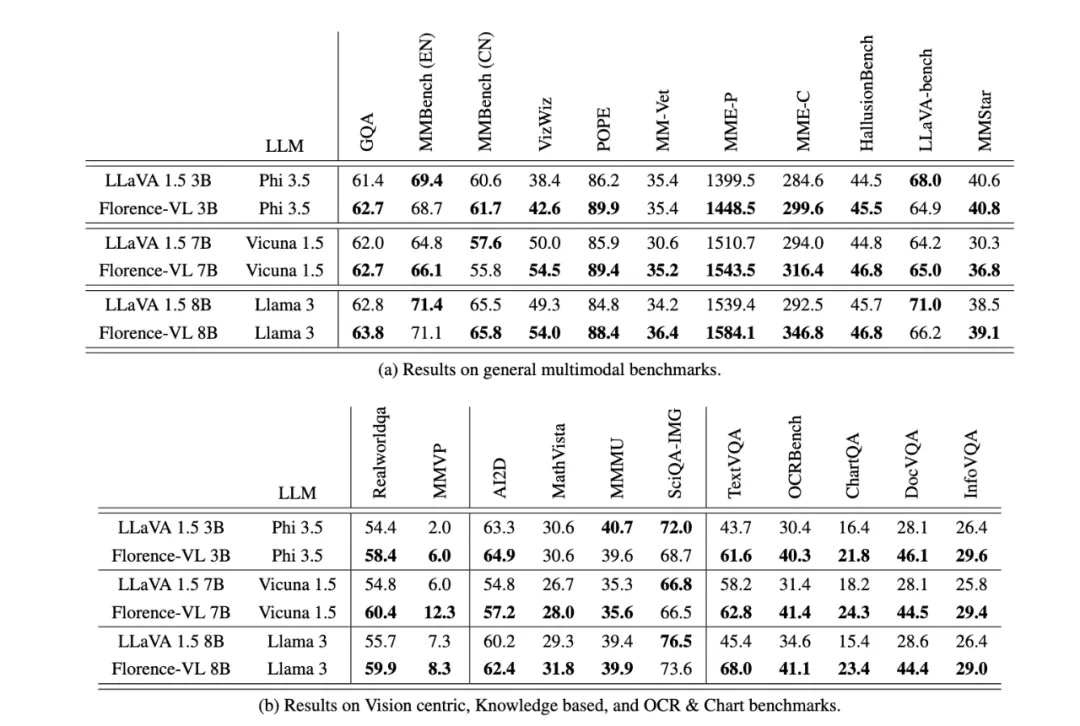
总结与展望
Florence-VL凭借其创新的生成式视觉编码器和深度-广度融合策略,在多模态大语言模型领域取得了显著进展。未来研究方向包括探索更先进的自适应融合策略,以根据不同任务动态调整特征融合的策略。
(脚注:[1])
以上就是Florence-VL来了!使用生成式视觉编码器,重新定义多模态大语言模型视觉信息的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 近期热点
近期热点 最新攻略
最新攻略












