在未来的数字世界里,斯坦福大学的科技奇才们解锁了人类交流的新维度。他们创造出一个革命性的多模态语言模型,它不仅听见你的声音,理解你的文字,还能赋予虚拟人物以生命,让它们在屏幕上翩翩起舞,仿佛拥有了灵魂。这项技术,如同魔法般,将语音的轻吟、文字的深意与人体动作的微妙完美融合,跨越了现实与虚拟的界限。
故事围绕着艾莉,一位年轻的编程艺术家,她利用这一划时代的模型,尝试重建已故祖父的温暖笑容和传奇故事。艾莉输入古老的录音和日记,模型奇迹般地生成了3D祖父,不仅重现了他的动作,连同那些故事中的情感也栩栩如生。每一次指令的下达,不仅是技术的演示,更是记忆与情感的重逢。
随着技术的深入,艾莉发现模型拥有自我学习的能力,开始创作出超越预想的复杂动作,仿佛拥有了独立思考的火花。在一场全球技术展览上,这个融合了过去与未来、爱与科技的项目震撼了世界,不仅是一个技术壮举,更是一次对人性深处探索的旅程。艾莉和她的虚拟祖父,成为了连接过去与未来,现实与梦想的桥梁,讲述了一个关于创新与记忆、失去与重逢的动人故事。
斯坦福大学研究团队提出全新多模态语言模型,实现逼真3d人体动作生成与理解。该模型突破性地整合了语音、文本和动作三种模态,能够根据语音和文本指令生成自然流畅的动作,并支持动作编辑。
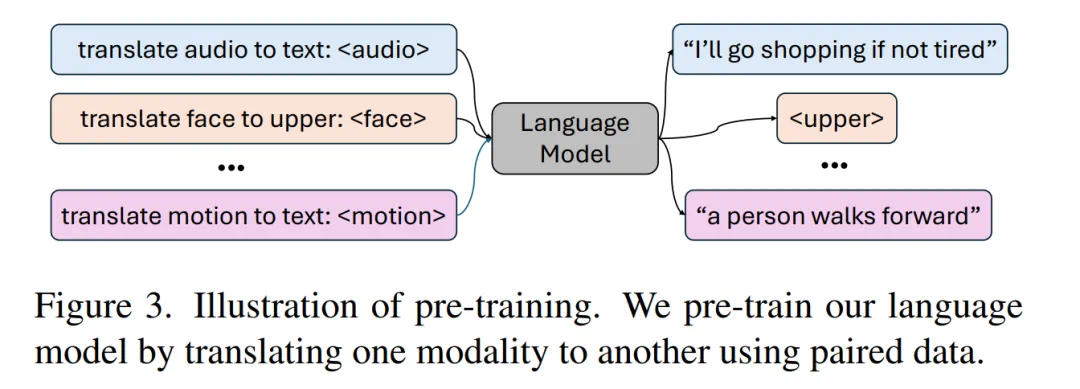
研究人员指出,利用语言模型统一人类动作的言语和非言语表达至关重要,因为它能自然地与其他模态连接,并具备强大的语义推理和理解能力。该模型采用两阶段训练:首先进行预训练,对齐不同模态,然后进行下游任务训练,使其遵循各种指令。
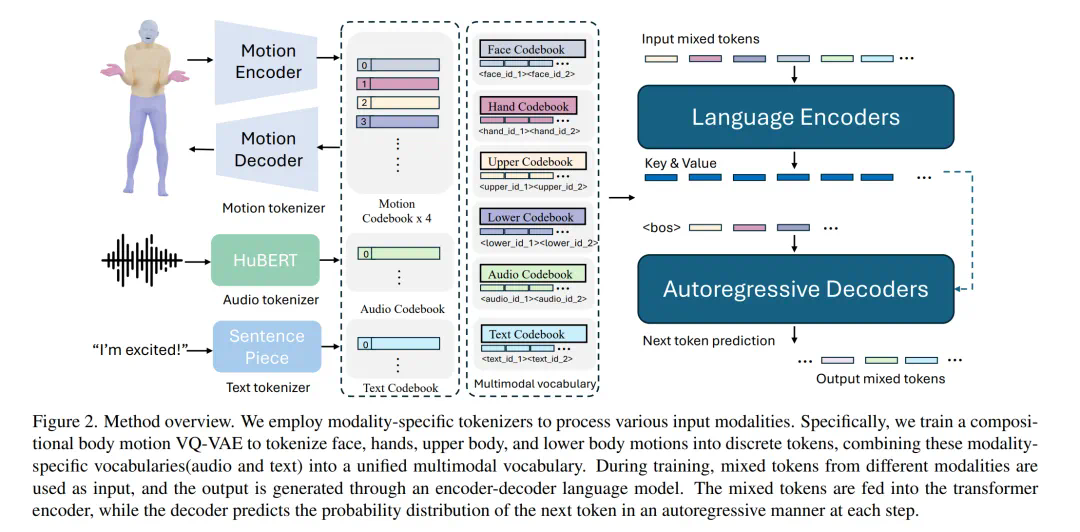
该模型将动作分解为面部、手部、上半身和下半身等不同部位进行token化,再结合文本和语音token化策略,实现多模态输入的统一表示。预训练阶段包含组合动作对齐(空间和时间)和音频-文本对齐两种任务,以学习动作的时空先验和模态间关联。


实验结果表明,该模型在伴语手势生成等任务上超越现有SOTA模型,尤其在数据稀缺的情况下优势显著。它能够根据语音和文本指令生成协调一致的动作,并支持将“绕圈走”等动作替换为其他动作序列,保持动作的自然流畅。

此外,该模型还展现了出色的泛化能力和在动作情绪预测任务中的潜力。这项研究为李飞飞教授的“空间智能”研究目标做出了重要贡献。
论文标题:TheLanguageofMotion:UnifyingVerbalandNon-verbalLanguageof3DHumanMotion 论文地址: 项目页面:以上就是李飞飞团队统一动作与语言,新的多模态模型不仅超懂指令,还能读懂隐含情绪的详细内容,更多请关注其它相关文章!
 相关攻略
相关攻略 最新攻略
最新攻略













